Pozdrav prijatelji! Oduvijek sam volio "pregledavati" spremište. I prije nekog vremena pronašao sam paket koji mnogima može pomoći u svakodnevnom radu. Meni osobno pomaže u pronalaženju članaka ili tekstova ili knjiga, u mojoj neredu /Dom.
Povuci je alat za pretraživanje cjelovitog teksta (od riječi do složenih logičkih izraza) pomoću prijateljskog grafičkog sučelja, s najmanje sofisticirane tehnike i nekim obaveznim vanjskim ovisnostima. Može se pokretati na mnogim operativnim sistemima sličnim UNIX-u i prilično je neovisan o radnom okruženju koje se koristi. Ne zahtijeva demon kao pozadinu za pretraživanje i indeksiranje. Kao pretraživač Xapian.
Da bismo instalirali Recoll, pokrećemo Synaptic i u okvir za tekst "Brzi filter”Kucamo oporaviti se i odmah će nam se pokazati. Za normalnu upotrebu u Debianu potrebno je samo instalirati taj paket.
Oni koji više vole Ubuntu, takođe mogu instalirati paket python-recoll, koji pruža modul za proširenje Recoll-ovih funkcionalnosti i upotrebu kao Ubuntu Unity objektiv.
Ipak, toplo preporučujemo da pristalice Ubuntua pročitaju članak Traženje gotovo svih vrsta datoteka u Ubuntuu sa Recoll-om, koji mi je poslao moj prijatelj Yoandy Pérez Cáceres (Kceres de humanOS). Taj je članak mnogo prijatniji od ovog.
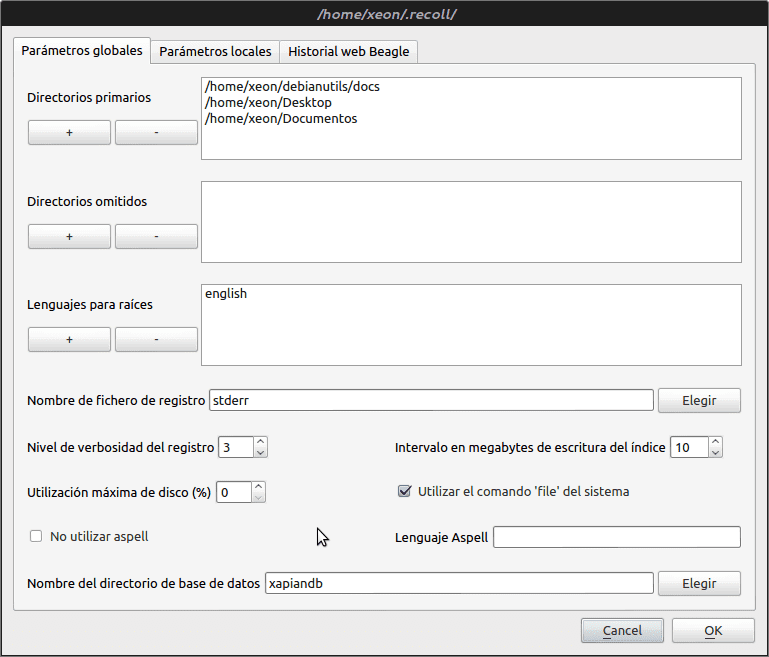
Jednom instaliran naći ćemo ga u grupi "Dodaci". Izvršimo ga i prvo što moramo učiniti je konfigurirati indeksiranje kroz opciju izbornika Postavke -> Postavke indeksiranja.
Kako potraga ne bi trajala toliko dugo i odgovarala našim interesima, uklanjamo virgulilla ~ (znači sve naše /Dom) primarnih direktorija i dodajte one koje smatramo potrebnima.
Grafičko sučelje vrlo je intuitivno i pozivamo sve da istraže blagodati ovog paketa. Provjerite sami potrošnju resursa kupljenih na pretraživačima koji su po defaultu instalirani s KDE4 ili s GNOME-školjkom.
Uz to, jednostavnost njegove instalacije i upotrebe, kao i vrlo kratak broj zavisnosti, čine ga idealnim za vaš specifičan rad na mašinama s malom snagom.
I do sljedeće avanture, prijatelji !!!.
Dakle, ovo je nešto poput onoga što Nepomuk radi? zvuči dobro za upotrebu s mojim openboxom.
Hvala na komentaru! I da, to je pretraživač za računare, ali sa mnogo nižom potrošnjom resursa
Zaista mislim da se neću mjeriti s Nepomukom. Vidim da ima podosta opcija, ali morate vidjeti da li je u stanju indeksirati svaki element prema onome što jeste. Nepomuk je ogroman projekt i mislim da Recoll neće doseći svoj nivo, barem ne za sada.
nepomuk je sporiji i više neispravan od Windows indeksera, a to već govori XD
Nepomuk nema nikakve veze sa Windows indekserom, ili sam barem tako ostao u sustavu Windows.
Nepomuk se puno poboljšao u KDE 4.10 i bit će mnogo brži u KDE 4.11 😀
Govore mi isto od 4.6 ..., bit će bolje i bla bla bla, i ne vidim koliko sam puta spustio slušalicu čitajući svoju japansku muzičku biblioteku XD
Da, koliko sam shvatio, potpuno su ga promijenili i prepisali, više ne koristi strige
Nepomuk ne prikazuje dio teksta, a kamoli da ga ističe, kada nešto tražite. Ovo je superiorno !!!
Ubio sam se tražeći tako nešto !!!!!
Ne znate koliko ste me obradovali !!!!!!!!
Čak sam pokušao instalirati određenog Goonepuka (ili nešto slično) koji je koristio Nepomuk za traženje teksta u Googleovom stilu, ali nije uspio.
Ali ovo je idealno (iz emocija ga još uvijek ne instaliram 🙂)
Mislio sam da nikada neću naći nešto slično, a čini se laganim, idealnim za moj XFCE (šteta što to ovisi. Qt, ali ne možeš sve u životu, ha).
Ne znam kako da ti zahvalim, opet si mi smisao života (pa, malo pretjerujem)
HVALA PUNO!!!!!!!!!!
Hvala vam na komentaru. Sretna sam što vam je poslužila. Sjećam se iz 90-ih programa koje su koristili za pretraživanja. Strašan !!!. Sada je riješen jednostavnim programom.
Svaka čast !!!
Ako je iz 90-ih, onda će zagarantovano biti sjajno, a samim tim i mnogo bolje (koliko znam, većina besplatnog softvera napravljenog 90-ih bila je sjajna).
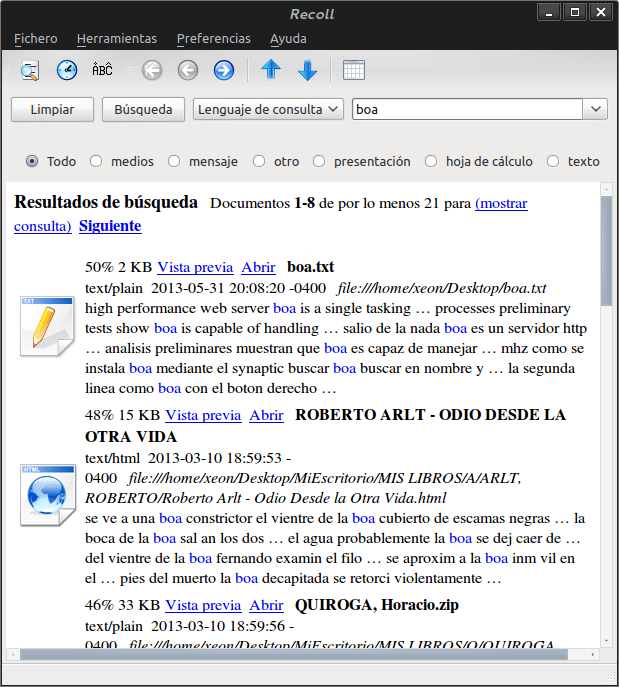
Hvala svima na komentaru !!! Povuci izvorno indeksira običan tekst, html, maildir, poštansko sanduče (Mozilla, Thunderbird i Evolution mail), gaim, Scribus, man stranice i dijagrame Dia. Uz pomoć dodataka kao što su iconv, xslproc, unzip, pdftotext, antiword i drugi, možete indeksirati i Abiword, Fb2, Kword, Microsoft Office Open XML, datoteke s nastavkom SVG, Gnumeric, Okular, pdf, MS Word, Wordperfect, Lyx, Powerpoint, Excel, CHM datoteke. Takođe može poslužiti kao dodatak Firefoxu za indeksiranje povijesti web stranica ili obradu priloga e-adresa.
Ne znam opseg drugih pretraživača, ali za moje potrebe postoji puno prednosti. 🙂
Pa, u Windows 7 se može naći u docx datotekama ako nisam zbunjen. Ali sigurno se zbunim. Ali ako podržava odt, to bi trebalo dokazati.
Dobro, ali rezultati su drugačiji.
Ne mogu se zasititi da dobro govorim o ovom programu. Koristim gtk okruženje i iz istog razloga bih mogao potražiti rješenje koje koristi biblioteke iz ove porodice, ali navodno moćna gtk alternativa, tracker, je užasna. Što se tiče Nepomuka, suludo je instalirati ga ako ne koristite KDE (zapravo, nema smisla to činiti), jer njegova instalacija nosi gotovo sav KDE. Uz to, izvorno sam ga testirao u KDE okruženju i istina je da me to ne uvjerava ni performansama ni rezultatima. Recoll zauzima malo resursa, savršeno indeksira i prikazuje rezultate na vrlo koristan način. Za sada ne mijenjam ovaj alat ni za što.
Pozdrav.
Hvala na komentaru !!!. Recoll odgovara, i daleko, mojim potrebama. Xapianov mehanizam - ili njegove biblioteke - koristi se u drugim aplikacijama poput Synaptic-a i čak ne znate kada indeksirate.
Upit: Koje okruženje radne površine koristite i koju temu koristite? Jer tema koju ste koristili u GNOME 3 u QEMU-KVM tutorialu je bila zaista super.
ako se ne varam, pretpostavljam da je to XFCE s temom Albatros (najbolji od svih)
@ eliotime3000, @gato: Pozdrav prije svega. Nakon korištenja cimeta nekoliko sedmica, vratio sam se u GNOME-ljusku. Da kritiziranoj Shell. I činit će se čudno, ali kao što sam rekao u 1. dijelu QEMU-KVM, za mene je to metak. Znaš šta? Najbolje sam se prilagodio i da uopće nisam mlad. 🙂 Dobio sam produžetke gnome-shell-classic-systray_0.1-0+20120306~webupd8~precise1_all.deb I to gnome-shell-frippery-0.4.1.tar.gz i istina je da mi GNOME 2. ne propušta skoro ništa. Tar datoteka, gz, sadrži 6 ekstenzija u koje se mora kopirati ~ / .local / share / gnome-shell / extensions /, ponovo pokrenite GDM3, a zatim pomoću gnome-tweak-alat postaviti okruženje. I @ gato, ako koristim albatros, koji se instalira sa paketom šiki-ljudska-tema i njegove zavisnosti.
Svejedno, navikao sam na GNOME-školjku i preporučujem je svima. Moglo bi me uzbuditi i objaviti post, posebno za novopridošle, o tome kako napraviti prilagođenu Debian radnu površinu za nas.
Odličan alat!
Veoma je dobro. Stvaranje baze podataka traje neko vrijeme, ali pretraživanje je vrlo brzo.
Čak traži riječi u LibreOffice i Inkscape datotekama (.svg). Vrlo je korisno kada ne znamo ime datoteke, ali znamo dio sadržaja. Hvala ti!
Hvala na komentaru, Joaquín !!!. Vrijeme potrebno za stvaranje baze podataka ovisi o broju mapa koje ste deklarirali u konfiguraciji. Međutim, ne znam jeste li provjerili da tijekom indeksiranja i kreiranja baze podataka možete normalno raditi.
čovek zaplenjen
A ako koristite Ubuntu, postoji sočivo zbog kojeg je rukovanje njime najlakša stvar na svijetu.
Inače, da biste ga instalirali u Ubuntu, ono što morate učiniti je instalirati pakete recoll (za program) i recoll-lens (za sočiva).
Detaljno objašnjenje kako instalirati Recoll na Ubuntu dato je u članku na koji sam se gore pozvao, "Traženje gotovo svih vrsta datoteka u Ubuntuu s Recoll-om". Hvala na komentaru !!!.
Zdravo,
Ja sam informatičar i radim u Gradskom vijeću Coria (Cáceres). Implementiramo Ubuntu i, između ostalih uslužnih programa, koristimo Recoll.
Ono što želim znati je kako ste došli do španske verzije.
Pozdrav i hvala.
Mislim da sam sama odgovorila.
U Ubuntu spremištima postoji verzija 1.17.3, a španski prijevod uveden je u verziji 1.19.3
Pozdrav.
Pozdrav anđeo !!!. Pa, u Debianu 7 "Wheezy" verzija je 1.17-3.2 i prevedena je. Očigledno ga je debianeros spakovao iz verzije prevedene na španski jezik kako bi se mogao koristiti ako je potrebno. Mislim da ga možete preuzeti s web stranice Debian.
Upravo sam otkrio spektakularnu opciju. Recoll se može izvršiti za indeksiranje datoteka bez potrebe za prijavom ili aktivnim grafičkim sučeljem.
Može se pokrenuti automatski pomoću naredbe recollindex -x -m. -X služi za rad bez aktivnog grafičkog sučelja (bez X-ova), a -m za nadgledanje datoteka u stvarnom vremenu (kada se jedna kreira ili modificira). Pored toga, možete izmijeniti konfiguracijsku datoteku recoll.conf, koja se obično nalazi u matičnoj .recoll mapi, kako bi vam rekla koje mape treba pratiti, itd.
Sve je ovo izvrsno za indeksiranje datoteka na serveru, na primjer.
Zatim unutar GUI-a možete ga natjerati da koristi vanjske indekse prilikom pretraživanja (u postavkama -> konfiguracija vanjskih indeksa).
Pored toga, kreirao sam malu skriptu za init.d kako bi indeksator automatski pokrenuo pokretanje servera.
Tako da sa radne površine mogu pretraživati datoteke indeksirane na serveru.
Poslednji
Izniman doprinos, prijatelju Andrés Sánchez !!!. Uzeću u obzir da ga primijenim na svojim poslužiteljima datoteka sa Sambom. Hvala na detalju dijeljenja vašeg otkrića.
Pozdrav od Federica
Nema na čemu, gospodine. O tome se radi, dijeleći naša otkrića.
Usput, pogledajte pomoć za konfiguriranje datoteke recoll.conf. Možete promijeniti staze indeksiranja (prema zadanim postavkama to čini samo kod kuće), preskočiti datoteke i mape unutar tih staza, odrediti hoće li slijediti simboličke veze, odrediti jezike (jezike) koji će se koristiti za indeksiranje, kodiranje datoteke, ako je indeksiranje osjetljivo na velika i mala slova, put na koji će se indeks spremiti (ovo je izvrsno za kasniji pristup indeksu s drugog računara, sve dok je put indeksa u dijeljenoj mapi) i mnoge druge opcije koje još nisam pokušao.
U putanji / usr / share / recoll / examples (barem na ubuntuu) nalaze se primjeri datoteka konfiguracije.
Pozdrav, ja sam korisnik OpenSuse (danas verzija 13.1) i kao alat za indeksiranje već godinama koristim Google Desktop! (Pročitao sam probleme koje ima i sigurnosne rupe, blablablabla,), ali do sada nisam vidio niti pronašao nešto što je na visini s obzirom na rezultate.
Recoll koristim manje od mjesec dana i otkad je toliko potpun, više mi ne funkcionira. Složen je za konfiguriranje, nije namijenjen uobičajenom korisniku koji ne razumije puno u naredbe i ostalo.
Izgleda vrlo obećavajuće, ali zasad nisam u potpunosti uvjeren.
Ako mi neko može pružiti ruku s malim problemom (rekao bih Flandriji).
U vrijeme instalacije, prije prvog indeksiranja kuće, odlučio sam dodati nekoliko udaljenih i sistemskih direktorija (/ usr / share, itd., / Mnt / unutarnji mrežni direktorij, / mnt / my disk lacie za sigurnosnu kopiju,)
Problem koji sam pronašao je taj što se, kada unesem tekst za jednostavno pretraživanje, on vrati kao rezultat, prvo oni koji se nalaze u mojim vanjskim direktorijima ("/ mnt / ....") I na kraju oni koji se nalaze u / home / moje ime.
Drugi problem je taj što kada unesem kao pretragu "DNI moje ime" (bez navodnika), neće vratiti nikakve rezultate ako odaberem filter "ime datoteke" kada se datoteka samo zove "DNI moje ime.jpg"
Da bi se datoteka pojavila, moram odabrati "sve termine ili bilo koji pojam"
Do sada je iz praktičnih razloga, brzine i jednostavnosti, Googleova radna površina i dalje najbolja, osim ako ne pronađem kako konfigurirati Recoll i kako odrediti prioritete datotekama u mom domu prilikom vraćanja rezultata.
Ako mi neko može pomoći ili mi reći gdje mogu pronaći jednostavan vodič (NE PRIRUČNIK ZA 50MIL stranica i na engleskom je jeziku)
Puno vam hvala na postu. VEOMA DOBRO.
PS: Nepomuk me nikada nije služio !! Nikad nisam vidio kako iz njega izvući sok i kako to djeluje. Posvuda razgovaraju o tome kako je dobro, ali nikada nisam nikoga vidio kako izvući maksimum iz toga i kako to primijeniti u praksi.