Hilsen venner, jeg er meget glad for at være med og deltage i hvad der er inden for min rækkevidde fra nu af i <° Desde Linux. Mit navn er Jathan, og jeg deler denne første post med jer baseret på dokumentation, som jeg lavede i den sociale service af mit fakultets IT-koordinering. Jeg håber, du finder det interessant, nyttigt og kommer med alle slags kommentarer.
Når vi i en tekstfil vil finde nøgleord til oprettelse af et tematisk indeks, analysere hovedidéerne til et værk eller et andet lignende formål, er vi nødt til at foretage søgninger ved hjælp af hvilke vi kan skelne mellem store og små bogstaver i ord samt en liste over disse, der fremhæver de ønskede tegn, såsom et bogstav, så vi kan finde nøgleord på en hurtigere og mere praktisk måde.
Denne dokumentation har til formål at præsentere og forklare brugen af en kvalitativ tekstanalyseapplikation og en teksteditor for at lette realiseringen af et tematisk indeks med fri software.
Den første del forklarer proceduren for installation LibreOffice og udførelse af AntConc i operativsystemet GNU / Linux og senere hvordan man gør det inden for Windows og Mac OS-systemer, mens det i de følgende dele uanset operativsystem vil blive forklaret, hvordan man bruger AntConc y LibreOffice Brug af eksempler til at oprette et emneindeks.
LibreOffice og AntConc på GNU / Linux


Den første ting, vi skal gøre, er at kontrollere, at vi har LibreOffice installeret på vores GNU / Linux-distribution. LibreOffice er en gratis multiplatform-kontorpakke, der er licenseret med GPL, og som hjælper os med at redigere tekstdokumenter, dias, regneark, databaser, tegninger og matematiske formler på en enkel og effektiv måde.
Hvis vi bruger Debian, Linux Mint, Trisquel, Ubuntu eller enhver anden distribution baseret på Debian, Vi behøver ikke længere håndtere installationen, da LibreOffice i de fleste af disse distributioner i deres nyeste versioner såvel som andre som Mageia, Fedora og OpenSUSE allerede er forudinstalleret, og du skal bare finde den og køre den fra applikationspanelet eller via kommandolinjen.
Hvis vi bruger Debian Squeeze 6.0, skal vi opdatere OpenOffice til LibreOffice ved at følge disse instruktioner: http://www.dobleseis.com.ar/instalar-libreoffice-3-en-debian-squeeze.
Efter at have sikret os, at vi har LibreOffice installeret på vores system, fortsætter vi nu med at besøge AntLab-webstedet, hvor vi kan finde nogle nyttige applikationer udviklet af Laurence Anthony til kvalitativ tekstanalyse og ordtilpasning med eksekverbare filer på tværs af platforme til GNU / Linux, Mac OS og Windows.

AntConc er en applikation skrevet i Perl-programmeringssproget, der giver os mulighed for at liste ord i alfabetisk rækkefølge eller efter udseendefrekvens, nøgleord, skabe overensstemmelse og grupper af ord fra en fil i almindeligt tekstformat og skelne mellem små og store bogstaver. For at downloade det skal du gå til dette link: http: //www.antlab.sci.waseda.ac.jp/antconc_index.html og vælge i den femte kolonne, hvor Tux-pingvinen vises, muligheden for at downloade AntConc 3.2.4u:

Når download af den valgte fil er afsluttet, åbner vi vores foretrukne filbrowser (Pcmanfm, Nautilus, Thunar, Dolphin eller en hvilken som helst anden) ved at åbne den gennem det grafiske miljøpanel, som vi bruger, eller ved at trykke på alt + f2 og skrive navnet i med små bogstaver og trykke på enter i slutningen og derefter oprette to mapper (mapper) i vores brugerkatalog, der navngiver en Applications_extras og en anden AntConc som en underkatalog til den første:

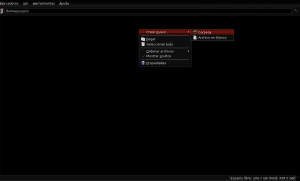
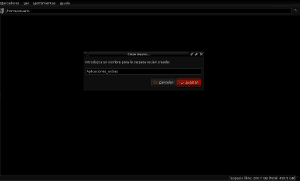
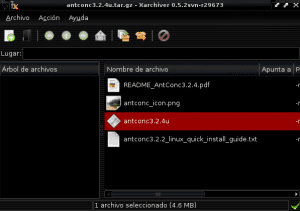
Nu går vi til den mappe, hvor filen antconc3.2.4u.tar.gz blev downloadet (i dette eksempel Downloads), og vi åbner filen med Xarchiver eller Fileroller for at pakke dens indhold ud i Antconc-biblioteket ved at vælge ekstraktindstillingen i vores filhåndtering og angiver katalogstien / hjem / bruger / Extra_Applications / AntConc:
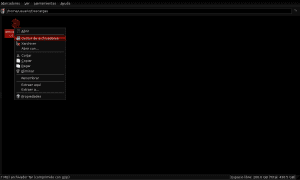
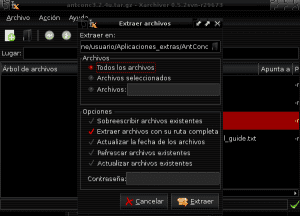
Når indholdet af antconc3.2.4u.tar.gz-pakken er blevet ekstraheret til AntConc-biblioteket i Applications_extras, identificerer vi antconc3.2.4u-filen for at give den tilladelse til udførelse ved at klikke på højre museknap, indtaste egenskaber og tillade udførelse af filen som et program:
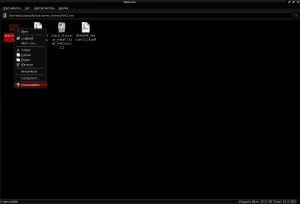
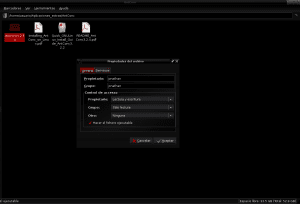
Og med dette skal vi kunne åbne AntConc ved at dobbeltklikke med musen på filen antconc3.2.4u.
Hvis vi foretrækker det, kan vi udføre al den foregående procedure gennem terminalen ved at udføre følgende kommandoer og ændre "bruger" med det navn, vi bruger i vores session:
Sådan oprettes mapper:
$ mkdir / home / user / Applications_extras (tryk på enter)
$ mkdir / home / user / Applications_extras / AntConc (tryk enter)
Skift til AntConc-biblioteket og udpak indholdet af antconc3.2.4u.tar.gz:
$ cd / home / user / Applications_extras / AntConc / (tryk enter)
$ tar -xzvf /home/usuario/Descargas/antconc3.2.4u.tar.gz(press enter)
Tillad at køre filen antconc3.2.4u som et program:
$ chmod + x antconc3.2.4u (tryk enter)
Og kør AntConc:
$ /home/usuario/Aplicaciones_extras/AntConc/antconc3.2.4u(press enter)
Uanset hvilken procedure vi vælger, hvis vi ønsker det, kan vi kopiere filen antconc3.2.4u til / usr / bin-biblioteket og give den de nødvendige tilladelser til at kunne køre AntConc fra terminalen eller med alt + f2, der kun skriver antconc3.2.4 .XNUMXu. Til dette udfører vi følgende kommandoer som superbruger med su eller sudo:
$ din
(vi skriver vores rodadgangskode og trykker på enter)
# cp /home/user/Extras_Applications/AntConc/antconc3.2.4u / usr / bin
# chmod a + rwx /usr/bin/antconc3.2.4u
# Afslut
Og nu, bare ved at køre antconc3.2.4u med vores bruger fra enhver terminalemulator, åbner AntConc som vist i det foregående billede.
$antconc3.2.4u
Brug AntConc til at liste ord efter et bestemt tegn
Efter at have allerede identificeret, hvordan man downloader og kører AntConc, vil vi nu give plads til at eksemplificere dets anvendelse til at finde nogle ord ved hjælp af en søgning i alfabetisk rækkefølge af tegn i både små og store bogstaver. Hvis du vil gå dybere ind i driften af AntConc og alle dens anvendelsesmuligheder, kan du se dokumentet README_AntConc3.2.4.pdf i vores bibliotek / hjem / bruger / Aplicaciones_extras / AntConc eller downloade det fra http: //www.antlab .sci.waseda.ac.jp / software / antconc335 / AntConc_readme.pdf samt konsultere onlinehjælpen eller se AntConc-videovejledningerne, der er tilgængelige på dens websted http://www.antlab.sci.waseda.ac. jp / antconc_index.html
AntConc kan kun arbejde med almindelige tekstfiler (".txt"), ".html", ".hml," ".xml" og dets eget format ".ant", så indholdet af det dokument, hvorfra vi fremstiller ordidentifikation, vi ændrer det fra dets oprindelige format i ".odt", ".rtf", ".pdf" eller noget andet til ".txt", der foretager et valg af alt indholdet, kopierer det og indsætter det i et nyt tekstdokumentplan, der kører vores foretrukne teksteditor (blandt andet Leafpad, Gedit, Vim, Emacs). I dette eksempel vil vi søge at oprette et tematisk indeks ud fra bogen «Collaborative Construction of Knowledge», hvorfra vi kan besøge dens websted: http://seminario.edusol.info/seco3/, og som vi kan downloade frit fra dette link: http: / /seminario.edusol.info/seco3/pdf/seco3.pdf

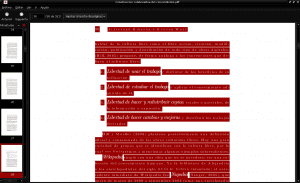
Når filen er downloadet, finder vi den i vores downloadsmappe, vi åbner den med vores pdf-dokumentfremviser (i dette eksempel Evince), vi vælger alt dens indhold ved at trykke på ctrl + a, vi kopierer det og indsætter det i en ny almindelig tekstdokument:

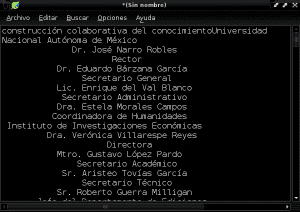
Og vi gemmer vores nye dokument i almindelig tekst med navnet "Construccion_colaborativa_del_conocimiento.txt" i dokumentmappen:
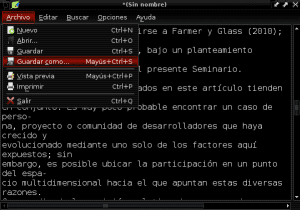
Nu udfører vi AntConc og fra den første fane øverst til venstre kaldet "File" åbner vi filen "Construccion_colaborativa_del_conocimiento.txt":
I venstre kolonne kaldet "Corpus Files" vises navnet på vores tekstfil nu, hvilket indikerer, at vi vil arbejde på denne fil, da vi i AntConc kan indlæse mere end en tekstfil og arbejde på dem sammen eller hver for sig:
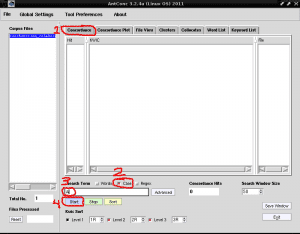
Hvad vi nu skal gøre er at liste alle de ord, der indeholder tegnet "A", for at identificere et nøgleord med dette store bogstav, da AntConc giver os muligheden for at skelne mellem små og store bogstaver, hvilket er meget nyttigt at identificere egennavne eller akronymer i listeform. Til dette placerer vi den første fane kaldet «Concordance» på højre side af «Corpus Files», fjern markeringen i feltet «Words» for at markere feltet «Case», begge i nederste højre side af «Search Term», skriver vi i feltet Søg under bogstavet A, og klik på det lilla rektangel, der siger "Start":
Og det viser resultaterne af det følgende. form:
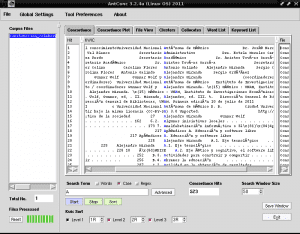
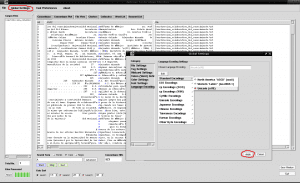
Som vi kan se, ligner nogle tegn skrevet med accenter svarende til ordet "Autónoma" i stedet for "Autónoma". Dette skyldes, at vi skal fortælle AntConc det passende kodningssprog til vores sprog, da AntConc ikke registrerer, at vi bruger spansk som standard. Til dette åbner vi fanen «Globlal Settings» øverst ud for «File», vi går til den sidste mulighed «Language Encoding Settings» i højre side, vi klikker på «Edit», vi vælger den første mulighed «Standard Encodings» Vi klik på den, vælg den tredje mulighed fra listen, der vises til højre "Unicode (utf8)", og klik på "Anvend" -boksen i nederste højre del af vinduet:
Efter at have anvendt ændringerne, klikker vi igen på det lilla rektangel på «Start», og de accenterede tegn vises nu læseligt:
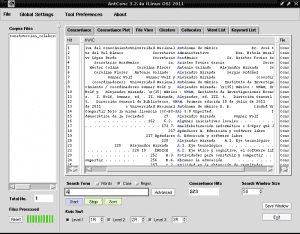
Nu gennemgår vi ordene med bogstavet A fremhævet i blåt for nem identifikation og ud fra vores overvejelser vælger vi dem, vi vil medtage i det tematiske indeks, for eksempel "Computer analfabetisme" i række 17 er den mest almindelige ord umiddelbart fundet at være det første, der henvises til i vores tematiske indeks fra indholdet af teksten til «Samarbejdskonstruktion af viden».
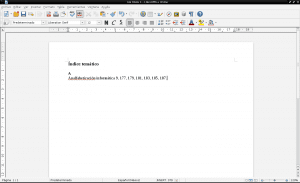
Vi vender tilbage til pdf-dokumentet «Samarbejdsopbygning af viden» for at finde på hvilke sider «Computer analfabetisme» vises ved at skrive «ctrl + f», skrive ordet «Analfabetisme» i søgefeltet og trykke «enter» i slutningen og det antal gange, der er nødvendigt for at finde det søgte ord på alle sider. Vi åbner et nyt dokument i LibreOffice Writer for at oprette vores emneindeks, eller hvis vi arbejder på indholdet af et dokument, der oprindeligt er i .odt, åbner vi dette dokument med LibreOffice, og vi opretter og redigerer kun dets emneindeks på enhver side :

Hvis vi også ønsker at identificere med AntConc, i hvilke sætninger "Computer analfabetisme" vises i hele indholdet af dokumentet "Construccion_colaborativa_del_conocimiento.txt", skriver vi "Computer analfabetisme" i søgefeltet, fjern markeringen af "Case", marker "Words" og klik på den for at "Start":
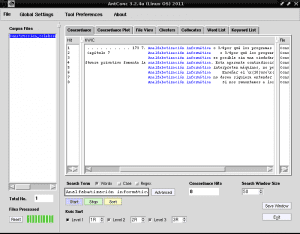
Hvis vi klikker på en af de rækker, der er fremhævet til «Computer analfabetisme» med blå farve, for eksempel i række 4, viser fanen «Filvisning» os fragmentet af teksten, hvor dette valg vises fremhævet med sort fra baggrunden:
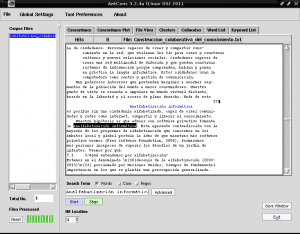
På denne måde er AntConc meget nyttigt for os, når vi har skrevet en bog, et essay eller et resumé, og vi ikke lavede et tematisk indeks parallelt eller systematisk at analysere de vigtigste ideer i et værk for at lette dets læsning.
Meget interessant værktøj .. ..Jeg vidste ikke om det .. og det er meget nyttigt for mig ..
Tak skal du have..
meget god artikel, interessant
Mange tak for delingen
Stort bidrag, meget nyttigt. At vide, at du kan have denne type værktøj i Linux, gør altid en forskel. Hilsen.
Fremragende indrejse. Jeg kan godt lide, at de udgiver denne type indhold!
Hej allesammen. Tak for dine kommentarer og en undskyldning for at kunne kommentere indtil videre. Jeg håber, at de, der har brugt vejledningen i praksis, ikke har haft problemer.