Un equipo de investigadores de varias universidades estadounidenses, israelíes y australianas ha desarrollado tres ataques dirigidos a navegadores web que permiten extraer información sobre el contenido del caché del procesador. Un método funciona en navegadores sin JavaScript y los otros dos evitan los métodos de protección existentes contra ataques a través de canales de terceros, incluidos los que se utilizan en el navegador Tor y DeterFox.
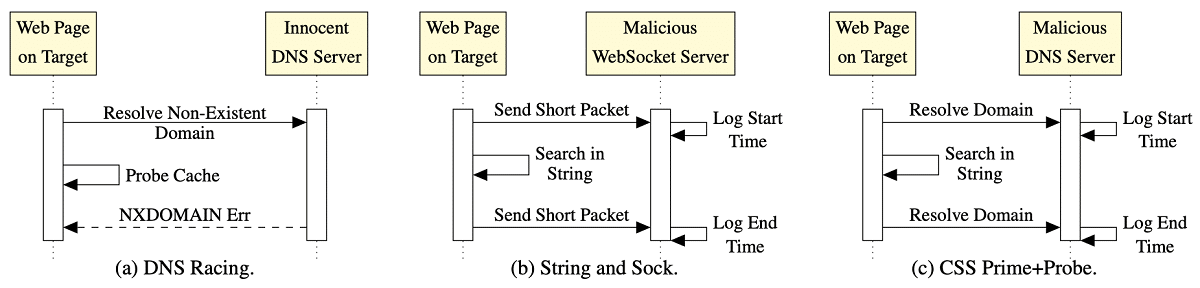
Para analizar el contenido de la caché en todos los ataques se utiliza el método «Prime+Probe», que implica llenar la caché con un conjunto de valores de referencia y determinar los cambios midiendo el tiempo de acceso a los mismos cuando se recargan. Para eludir los mecanismos de seguridad presentes en los navegadores, que impiden la medición precisa del tiempo, en dos versiones se apela a un servidor DNS o WebSocket atacante controlado, que lleva un registro del tiempo de recepción de las solicitudes. En una realización, el tiempo de respuesta de DNS fijo se usa como referencia de tiempo.
Las mediciones realizadas mediante servidores DNS externos o WebSocket, gracias al uso de un sistema de clasificación basado en aprendizaje automático, fueron suficientes para predecir valores con una precisión del 98% en el escenario más óptimo (en promedio 80-90%). Los métodos de ataque se han probado en varias plataformas de hardware (Intel, AMD Ryzen, Apple M1, Samsung Exynos) y han demostrado ser versátiles.
La primera variante del ataque DNS Racing utiliza una implementación clásica del método Prime+Probe utilizando matrices JavaScript. Las diferencias se reducen al uso de un temporizador externo basado en DNS y un controlador de error que se activa cuando se intenta cargar una imagen de un dominio inexistente. El temporizador externo permite ataques Prime+Probe en navegadores que restringen o deshabilitan por completo el acceso del temporizador de JavaScript.
Para un servidor DNS alojado en la misma red Ethernet, la precisión del temporizador se estima en aproximadamente 2 ms, lo que es suficiente para llevar a cabo un ataque de canal lateral (a modo de comparación: la precisión del temporizador estándar de JavaScript en el navegador Tor se ha reducido a 100 ms). Para el ataque, no se requiere control sobre el servidor DNS, ya que el tiempo de ejecución de la operación se selecciona para que el tiempo de respuesta del DNS sirva como una señal de una finalización anticipada de la verificación (dependiendo de si el controlador de error se activó antes o después). , se concluye que la operación de verificación con la caché está completada) …
El segundo ataque «String and Sock» está diseñado para eludir las técnicas de seguridad que restringen el uso de matrices de JavaScript de bajo nivel. En lugar de matrices, String and Sock emplea operaciones con cadenas muy grandes, cuyo tamaño se elige para que la variable cubra toda la caché LLC (caché de último nivel).
A continuación, utilizando la función indexOf(), se busca una pequeña subcadena en la cadena, que inicialmente está ausente en la cadena original, es decir, la operación de búsqueda da como resultado una iteración en toda la cadena. Dado que el tamaño de la línea corresponde al tamaño de la caché LLC, el escaneo permite realizar una operación de verificación de la caché sin manipular matrices. Para medir los retrasos, en lugar de DNS, se trata de una apelación a un servidor WebSocket atacante controlado por el atacante: antes del inicio y después del final de la operación de búsqueda, las solicitudes se envían en la cadena,
La tercera versión del ataque «CSS PP0″a través de HTML y CSS, y puede funcionar en navegadores con JavaScript desactivado. Este método se parece a «String and Sock» pero no está vinculado a JavaScript. El ataque genera un conjunto de selectores CSS que buscan por máscara. La gran línea original que llena el caché se establece mediante la creación de una etiqueta div con un nombre de clase muy grande, en el cual dentro hay un conjunto de otros divs con sus propios identificadores.
Cada uno de estos divs anidados tiene un estilo con un selector que busca una subcadena. Al renderizar la página, el navegador primero intenta procesar los divs internos, lo que da como resultado una búsqueda en una cadena grande. La búsqueda se realiza utilizando una máscara que obviamente falta y conduce a una iteración de toda la cadena, después de lo cual se activa la condición «no» y se intenta cargar la imagen de fondo.