Greetings friends, I am very happy to join and participate in whatever is within my reach from now on in <° Desde Linux. My name is Jathan and I share with you this first entry based on documentation that I did in the social service of the IT coordination of my faculty. I hope you find it interesting, useful, and make all kinds of comments.
When in a text file we want to find keywords for the creation of a thematic index, analyze the main ideas of a work or some other similar purpose, we need to do searches by means of which we can distinguish between uppercase and lowercase characters within the words, as well as a list of these highlighting the desired characters such as a letter so that we can find keywords in a faster and more practical way.
The present documentation aims to present and explain the use of a qualitative textual analysis application and a text editor to facilitate the creation of a thematic index with Free Software.
In the first part, the procedure for the installation of LibreOffice and the execution of AntConc within the operating system GNU / Linux and later how to do it within Windows and Mac OS systems, while in the following parts regardless of the operating system, it will be explained how to use AntConc y LibreOffice Using examples to create a subject index.
LibreOffice and AntConc on GNU / Linux


The first thing we need to do is verify that we have LibreOffice installed on our GNU / Linux distribution. LibreOffice is a free multiplatform office suite licensed with GPL and that helps us to edit text documents, slides, spreadsheets, databases, drawings and mathematical formulas in a simple and efficient way.
If we are using Debian, Linux Mint, Trisquel, Ubuntu or any other distribution based on Debian, We will no longer have to deal with its installation since in most of these distributions in their most recent versions as well as others such as Mageia, Fedora and OpenSUSE, LibreOffice is already pre-installed and you just have to find it and run it from the applications panel or by command line.
If we are using Debian Squeeze 6.0 we have to update OpenOffice to LibreOffice following these instructions: http://www.dobleseis.com.ar/instalar-libreoffice-3-en-debian-squeeze.
After making sure we have LibreOffice installed on our system, we will now proceed to visit the AntLab website where we can find some useful applications developed by Laurence Anthony for qualitative text analysis and word matching with cross-platform executable files for GNU / Linux, Mac OS and Windows.

AntConc is an application written in the Perl programming language that allows us to list words in alphabetical order or by frequency of appearance, keywords, make concordances and groups of words from a file in plain text format, distinguishing between lowercase and uppercase characters. To download it, go to this link: http: //www.antlab.sci.waseda.ac.jp/antconc_index.html and select in the fifth column where the Tux penguin appears the option to download AntConc 3.2.4u:

When the download of the selected file is finished, we open our preferred file browser (Pcmanfm, Nautilus, Thunar, Dolphin or any other) by opening it through the graphical environment panel that we use or by pressing alt + f2, writing its name in lowercase and hitting enter at the end and then create two directories (folders) within our user directory, naming one Applications_extras and another AntConc as a subdirectory of the first:

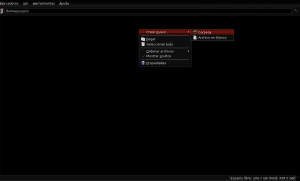
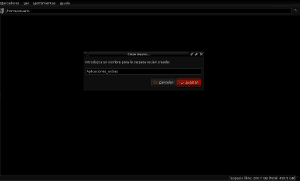
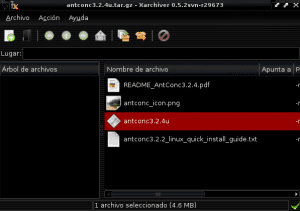
Now we go to the directory where the antconc3.2.4u.tar.gz file was downloaded (being in this example Downloads) and we open the file with Xarchiver or Fileroller to unzip its content to the Antconc directory by selecting the extract option in our file manager and indicating the directory path / home / user / Extra_Applications / AntConc:
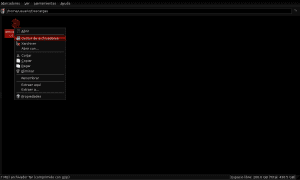
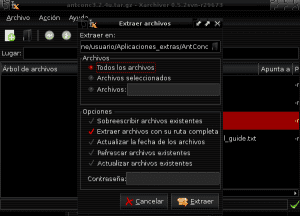
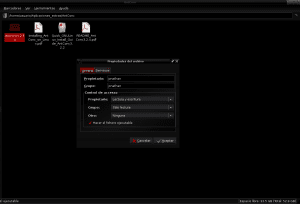
Once the content of the antconc3.2.4u.tar.gz package has been extracted to the AntConc directory within Applications_extras, we identify the antconc3.2.4u file to give it execution permissions by clicking the right mouse button, enter properties and allow the execution of the file as a program:
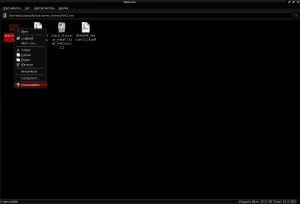
And with this we should be able to open AntConc by double clicking with the mouse on the antconc3.2.4u file.
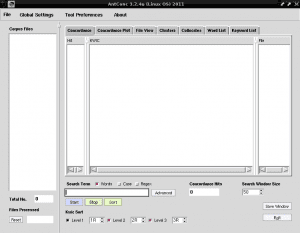
If we prefer, we can do all the previous procedure through the terminal by executing the following commands and changing "user" by the name we use in our session:
To create the directories:
$ mkdir / home / user / Applications_extras (press enter)
$ mkdir / home / user / Applications_extras / AntConc (press enter)
Change to the AntConc directory and extract the content of antconc3.2.4u.tar.gz:
$ cd / home / user / Applications_extras / AntConc / (press enter)
$ tar -xzvf /home/usuario/Descargas/antconc3.2.4u.tar.gz(press enter)
Allow to run the antconc3.2.4u file as a program:
$ chmod + x antconc3.2.4u (hit enter)
And run AntConc:
$ /home/usuario/Aplicaciones_extras/AntConc/antconc3.2.4u(press enter)
Regardless of the procedure we choose, if we wish, we can copy the antconc3.2.4u file to the / usr / bin directory and give it the necessary permissions to be able to run AntConc from the terminal or with alt + f2 writing only antconc3.2.4u. For this we execute the following commands as superuser with su or sudo:
$ su
(we write our root password and hit enter)
# cp /home/user/Extras_Applications/AntConc/antconc3.2.4u / usr / bin
# chmod a + rwx /usr/bin/antconc3.2.4u
# exit
And now, just by running antconc3.2.4u with our user from any terminal emulator, AntConc will open as shown in the previous image.
$antconc3.2.4u
Using AntConc to list words by a specific character
Having identified how to download and run AntConc, now we will give way to exemplify its use for locating some words by means of a search in alphabetical order of characters in both lowercase and uppercase. If you want to go deeper into the operation of AntConc and all its possibilities of use, you can consult the document README_AntConc3.2.4.pdf in our directory / home / user / Aplicaciones_extras / AntConc or download it from http: //www.antlab .sci.waseda.ac.jp / software / antconc335 / AntConc_readme.pdf, as well as consult the online help or watch the AntConc video tutorials available on its website http://www.antlab.sci.waseda.ac. jp / antconc_index.html
AntConc can only work with plain text files (".txt"), ".html", ".hml," ".xml" and its own format ".ant", so the content of the document from which we will make the word identification, we will change it from its original format in ".odt", ".rtf", ".pdf" or some other to ".txt" making a selection of all the content, copying and pasting it to a new text document plane running our preferred text editor (Leafpad, Gedit, Vim, Emacs, among others). In this example we will seek to create a thematic index from the book «Collaborative Construction of Knowledge» from which we can visit its website: http://seminario.edusol.info/seco3/ and which we can download freely from this link: http: / /seminario.edusol.info/seco3/pdf/seco3.pdf

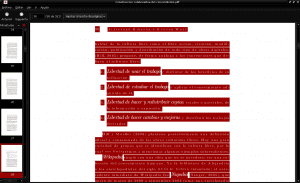
Once the file is downloaded, we locate it in our downloads directory, we open it with our pdf document viewer (in this example Evince), we select all its content by pressing ctrl + a, we copy it and paste it into a new plain text document :

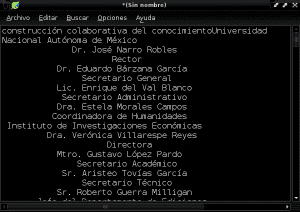
And we save our new document in plain text with the name of «Construccion_colaborativa_del_conocimiento.txt» in the Documents directory:
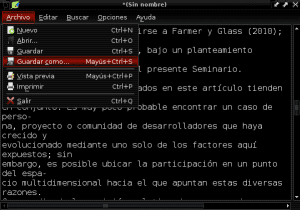
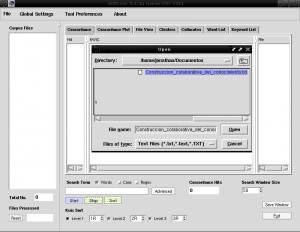
Now we run AntConc and from the first upper left tab called "File" we open the file "Construccion_colaborativa_del_knowledge.txt":
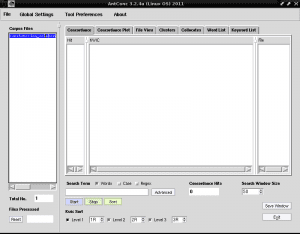
In the left column called "Corpus Files" the name of our text file will now appear, indicating that we will be working on this file, since in AntConc we can load more than one text file and work on them together or separately:
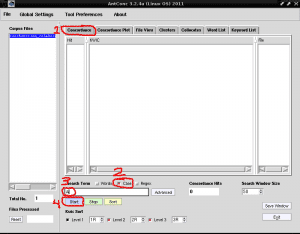
Now what we will do is list all the words that contain the character "A", to identify a keyword with this capital letter, since AntConc offers us the possibility of distinguishing lowercase and uppercase letters, this being very useful to identify proper names or acronyms in list form. For this we place the first tab called «Concordance» on the right side of «Corpus Files», uncheck the «Words» box to mark the «Case» box, both in the lower right side of «Search Term», we write in the field Search below the letter A and click on the purple rectangle that says "Start":
And it will list the results of the following. shape:
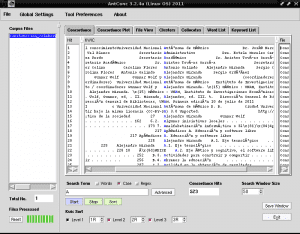
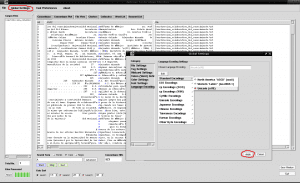
As we can see, some characters written with accents appear similar to the word "Autónoma" instead of "Autónoma". This is because we must tell AntConc the appropriate coding language for our language, since AntConc does not detect that we are using Spanish by default. For this we open the tab «Globlal Settings» at the top next to «File», we go to the last option «Language Encoding Settings» on the right side we click on «Edit» we select the first option «Standard Encodings »We click on it, select the third option from the list that appears on the right" Unicode (utf8) "and click on the" Apply "box in the lower right part of the window:
After applying the changes, click again on the purple rectangle of «Start» and the accented characters will now appear legibly:
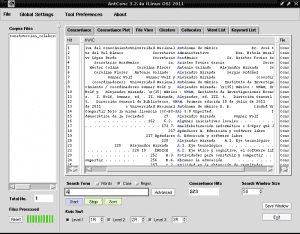
Now we are reviewing the words with the letter A highlighted in blue for easy identification and based on our considerations, we are selecting those that we want to include in the thematic index, for example "Computer illiteracy" in row number 17 being the most common word immediate found to be the first to be referred to in our thematic index from the content of the text of «Collaborative construction of knowledge».
We return to the pdf document «Collaborative construction of knowledge» to find in which pages «Computer illiteracy» appears by typing «ctrl + f», writing the word «Illiteracy» in the search field and pressing «enter» at the end and the number of times that is necessary to locate the searched word on all pages. We open a new document in LibreOffice Writer to create our subject index or if we are working on the content of a document that is originally in .odt, we open that document with LibreOffice and we will only create and edit its subject index on any page:

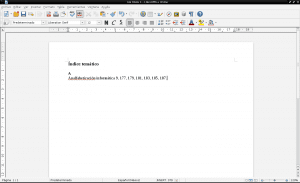
If we also want to identify with AntConc in which sentences "Computer illiteracy" appears in all the content of the document "Construccion_colaborativa_del_conocimiento.txt", we write "Computer illiteracy" in the search field, uncheck "Case", mark "Words" and click it to "Start":
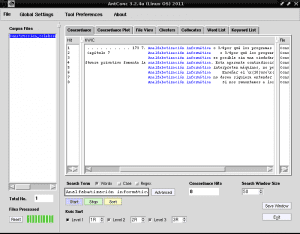
If we click on any of the rows highlighted to «Computer illiteracy» with blue color, for example in row 4, in the «File View» tab it will show us the fragment of the text where this selection appears highlighted with black from background:
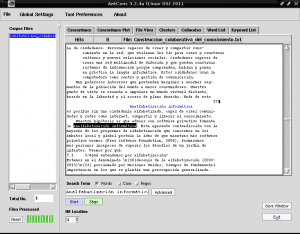
In this way, AntConc is very useful to us when we have written a book, essay or summary and we did not make a thematic index in parallel or to systematically analyze the main ideas of a work to facilitate its reading.
Very interesting tool .. ..I didn't know about it .. and it is very useful to me ..
Thank you ..
very good article, interesting
Thank you very much for sharing
Great contribution, very useful. Knowing that you can have these types of tools in Linux always makes a difference. Regards.
Excellent entry. I like that they publish this type of content!
Hello everyone. Thanks for your comments and an apology for being able to comment so far. I hope that those who have implemented the tutoring have not had any problems.