
빅 데이터, 자유 소프트웨어 및 오픈 소스 : 사용 가능한 애플리케이션
빅 데이터는 대용량 데이터 관리와 관련된 기술적 개념입니다., 구조화 및 비 구조화, 현재 대기업, 기술, 과학 및 정부 부문에서 처리하고 있습니다.
말할 때 빅 데이터, 중요한 것은 데이터의 양이 아니라 조직이 데이터로 수행하는 작업입니다. 관련 기술인 빅 데이터는이를 분석하여 더 나은 의사 결정, 움직임 및 전략으로 이어지는 아이디어를 얻을 수 있습니다. 그리고이 측면에서 자유 소프트웨어 (SL)와 오픈 소스 (CA)는이 기술에 많은 기여를했습니다., 개발 된 많은 애플리케이션이이 개발 형식으로 구현 되었기 때문입니다.

빅 데이터 및 자유 소프트웨어
당업자에게는 이미 잘 알려져있다. 자유 소프트웨어, 개발 모델, 철학은 소프트웨어 제품을 중심으로 자유롭게 사용, 수정 및 배포 할 수있는 기술을 만드는 데 기반을두고 있습니다. 그리고 오픈 소스는 자유 소프트웨어 개발에있어 중요한 요소입니다. 제품 자유와 시민의 윤리보다는 이러한 개발 역학의 실질적인 이점에 초점을 맞추기 때문입니다.
따라서 SL / CA는 빅 데이터 수행 수단으로 기여, 빅 데이터는 기술 개발의 가속화 된 확장의 이점뿐만 아니라 빅 데이터가 가져 오는 정보에 대한 액세스의 자유를 위해 이러한 요소를 간접적으로 보완합니다.

빅 데이터 란?
개념
소프트웨어 및 기술 개발의 위대한 업적 중 하나 인 IBM, 빅 데이터는 다음과 같습니다.
«... 너무 많은 시간이 걸리고로드 비용이 많이 드는 막대한 양의 데이터 (구조화, 비 구조화 및 반 구조화)를 설명하는 데 사용되는 이해 및 의사 결정에 대한 새로운 접근 방식의 문을 연 기술 분석을 위해 관계형 데이터베이스로.
골
빅 데이터의 기술은 가능한 데이터 분석의 전체 스펙트럼을 포괄한다는 목표로 탄생했습니다.즉, 현재 및 다른 기술로 존재하고 해결되는 것뿐만 아니라 다음과 같은 기존 기술로 해결되지 않는 것 모두를 포함합니다. 대용량 데이터 저장 및 관리 매우 특정한 특성을 가지고 있습니다.
데이터
입찰 데이터는 일반적으로 다음과 같은 특성으로 정의되는 대량의 데이터를 처리합니다.
- 볼륨 : 여러 소스의 데이터 크기.
- 속도 : 여러 소스의 데이터가 도착하여 관리되는 속도.
- 종류: 여러 소스에서 분석 된 데이터의 형식.
내 말은, 일반적으로 구조화, 반 구조화 및 비 구조화 데이터로 구성된 데이터 볼륨, 일반적으로 Tera, Peta 또는 Exa와 같은 대량 접두사로 설명되는 대량으로 처리됩니다.
인터넷과 같은 모든 종류의 소스에서 (소셜 네트워크, 디지털 미디어, 웹 사이트 및 데이터베이스), 하드웨어 (휴대폰, 멀티미디어 플레이어, 포지셔닝 시스템, 민간 및 산업용 디지털 센서 등) 및 조직 (개인 및 공공, 상업, 정부 및 커뮤니티).

의의
빅 데이터를 조직에 유용한 기술로 만드는 이유 (개인 및 공공, 상업, 정부 및 커뮤니티), 귀중한 정보를 제공한다는 사실입니다. 질문조차하지 않은 질문에 대한 정확하고 신뢰할 수있는 답변이되는 경우가 많습니다. 특정 상황이나 문제. 즉, 일반적으로 수집 및 관리되는 동일한 정보에서 발생하는 측면에서 유용성이 종종 보입니다.
많은 양의 정보를 처리하면 가장 적절한 방식으로 처리 된 데이터를보다 쉽게 형성하거나 테스트 할 수 있습니다. 또는 관리자가 적절하다고 간주하는 것을 지정합니다. 이를 통해 빅 데이터를 사용하는 조직은보다 이해하기 쉬운 방식으로 문제를 식별 할 수 있습니다.
방대한 양의 데이터를 수집하고 그 내에서 추세를 검색하기위한 후속 분석을 통해 조직은보다 효과적이고 효율적으로 작업 할 수 있습니다., 훨씬 더 빠르고 매끄럽고 적시에 이동합니다. 또한 문제가 발생하기 전에 문제 영역을 제거하여 혜택, 평판 또는 지원을 잃을 수 있습니다.
이점
빅 데이터는 조직이 데이터를 훨씬 더 잘 관리하는 데 도움이되며,이를 통해 구성원 (클라이언트 또는 시민)에게 새로운 긍정적이거나 생산적인 기회를 식별 할 수 있습니다. 그리고 이것은 결과적으로 더 스마트하고 효율적인 행동으로 이어지며, 시간 / 노동 및 돈을 절약하며 종종 관련된 모든 사람의 행복으로 이어집니다. 빅 데이터를 사용하면 일반적으로 다음과 같은 방식으로 수행되는 활동에 가치가 추가됩니다.
- 비용 절감 : 대용량 데이터의 저장 및 관리.
- 시간 단축 : 의사 결정의 효율성과 효율성 향상.
- 신제품 및 서비스 : 사용자 (클라이언트 및 / 또는 시민)의 요구와 문제를 측정하고 예측할 수있는 능력으로 만족도가 높아집니다.
혜택
잘 사용 된 빅 데이터는 종종 거의 실시간으로 실패, 문제 및 결함의 근본 원인을 파악할 수 있습니다. 그러나 그것을 고려하는 것입니다 빅 데이터 기술은 그 자체로 만병 통치약이 아닙니다.. 그래서 다음과 같은 또 다른 위대한 기술을 인용합니다. 신탁, 다음을 추가 할 수 있습니다.
“빅 데이터의 가치를 확인하는 것은 분석을 의미 할뿐만 아니라 (이미 그 자체로도 이점입니다). 분석가, 비즈니스 사용자 및 경영진이 올바른 질문을하고, 패턴을 식별하고, 정보에 입각 한 결정을 내리고, 행동을 예측해야하는 전체 발견 프로세스입니다.

빅 데이터를위한 SL / CA 애플리케이션
연구, 테스트 및 구현을 위해 언급 할 가치가있는 자유 소프트웨어 및 오픈 소스 응용 프로그램은 다음과 같습니다.
관련
- Apache Hadoop : HDFS (Hadoop Distributed File System), Hadoop MapReduce 및 Hadoop Common으로 구성된 오픈 소스 플랫폼입니다.
- Avro : 직렬화 서비스를 제공하는 Apache 프로젝트.
- 카산드라 : 스토리지 모델을 기반으로하는 분산 된 비 관계형 데이터베이스 , Java로 개발되었습니다.
- Chukwa : 이벤트 로그의 대규모 수집 및 분석을 위해 설계된 소프트웨어입니다.
- 수로 : 데이터를 한 소스에서 다른 위치로 보내는 것이 주요 임무 인 소프트웨어.
- HBase : HDFS에서 실행되는 열 기반 데이터베이스 (열 지향 데이터베이스).
- 하이브 : 분산 환경에 저장된 대용량 데이터의 관리를 용이하게하는 "데이터웨어 하우스"인프라입니다.
- Jaql : 대량의 정보를 처리하도록 설계된 JSON 형식의 데이터를 활용할 수있는 기능적이고 선언적인 언어입니다.
- Lucene : 텍스트 인덱싱 및 검색을위한 라이브러리를 제공하는 소프트웨어입니다.
- Oozie : 워크 플로와 각 프로세스 간의 조정을 단순화하는 오픈 소스 프로젝트입니다.
- 돼지: Hadoop 사용자가 모든 데이터 세트를 분석하는 데 더 집중하고 MapReduce 프로그램 구축에 소요되는 시간을 줄일 수있는 소프트웨어입니다.
- ZooKeeper : 클러스터 전체의 프로세스가 직렬화되거나 동기화되도록 애플리케이션에서 사용할 수있는 중앙 집중식 인프라 및 서비스입니다.
독립적
잘 알려져 있지만 오픈 소스 플랫폼 인 Hadoop과 관련이없는 기타는 다음과 같습니다.
- Elasticsearch : 전체 텍스트 기반 검색 및 분석 엔진.
- MongoDB : 문서 데이터 모델을 기반으로하는 NoSQL 데이터베이스.
- 카산드라 : NoSQL 데이터베이스 관리를 위해 설계된 Apache 오픈 소스 프로젝트입니다.
- CouchDB : 쉬운 접근성과 다양한 웹 호환성을위한 공통 표준을 기반으로하는 오픈 소스 NoSQL 데이터베이스입니다.
- Solr : Lucene 프로젝트 Java 라이브러리를 기반으로하는 오픈 소스 검색 엔진.
기타 RDBMS 도구 : MySQL Cluster 및 VoltDB.
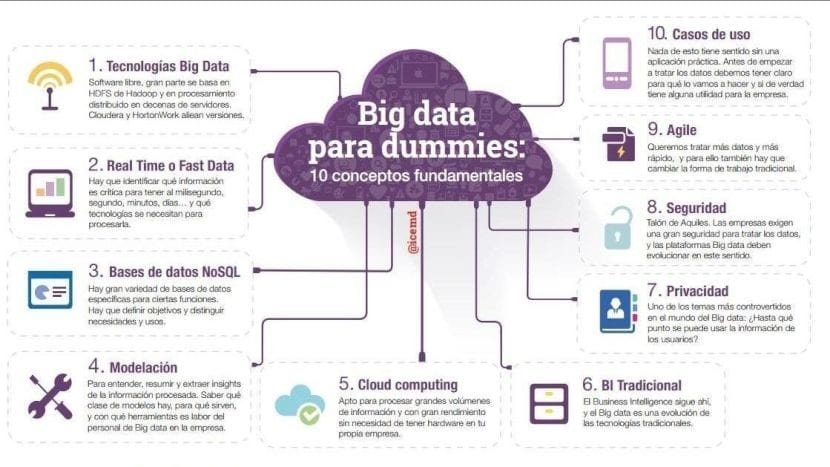
결론
우리의 현재 (그리고 바로 다음) 시간은 개별적으로 라기보다는 전체적으로 말할 필요가있는 높고 증가하는 대량의 데이터에 잠기거나 빠져 있습니다. 따라서 현재와 미래에 빅 데이터 기술을 사용하면 인류 전체를 포함한 사회가 자신을 발견하는 데 수년이 걸렸을 수있는 무한한 사물 (사건 또는 발명품)을 발견하는 데 도움이 될 것입니다. , 이것을 사용하지 않고.
이후 빅 데이터와 그 도구는 충분한 분석 속도를 제공합니다 신속하게 얻은 결과를 분석하고 필요한만큼 짧은 시간에 재 작업하여 도달하려는 실제 또는 가장 가까운 값을 찾습니다. 빅 데이터의 주제가 흥미 로웠다면이 보고서를 읽고 주제를 좀 더 확장 할 수 있습니다. BBVA.