오늘 우리는 현상을 경험하고 있습니다 빅 데이터, 우리는 무한한 수의 소스에서 엄청난 양의 데이터를 얻을 수 있습니다. 이 방대한 양의 데이터는 많은 이점을 가져다 주지만 많은 문제를 야기합니다. 가장 일반적인 것 : 대량 데이터 세트의 응답 시간.
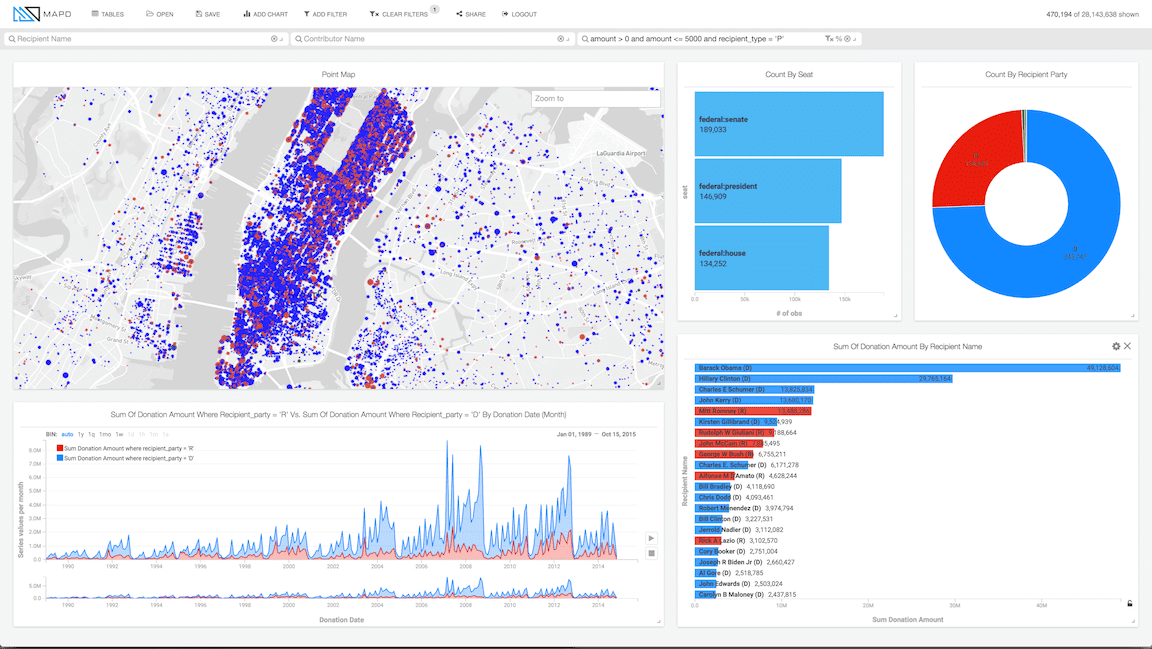
맵디 분석 데이터베이스 분야에서 빠른 속도를 제공하기 위해 탄생했습니다. 처리하도록 설계 밀리 초 안에 수조 개의 레코드 제공하는 컴퓨팅 파워를 활용 GPU. 그래픽 카드에서 사용할 수있는 모든 하드웨어 및 소프트웨어 기능을 최대한 활용하도록 정밀하게 구축 된이 소프트웨어는 분석가와 데이터 과학자에게 이전에 이러한 목적에 사용 된 기술보다 약 3 배 (x1000)의 응답 시간을 제공합니다. GPU의 병렬 처리 (최신 GPU에서 약 80000 개 코어) 및 대용량 메모리 대역폭 (약 8Gbps)을 활용하여 선형 대수 및 데이터베이스 검색을 수행하고 LLVM을 사용하여 각각 실시간으로 컴파일합니다. 가장 많이 참조 된 데이터를 GPU 캐시 (고속 DDR5 메모리)에 보관하는 것 외에도
빅 데이터 세계에서 파일의 쓰기 및 보존에 따라 기존 데이터베이스는 사용되지 않는다는 사실을 기억해야합니다. 이러한 데이터베이스는 하드 디스크에 과도한 양의 I / O 작업을 유발할 수 있기 때문입니다. 수십억 개의 기록을 분석하기 위해 인 메모리 데이터베이스, Apache Spark와 같습니다. 그러나 필요한 메모리 양과 원하는 성능을 얻으려면 서버 클러스터가 필요하며 이것이 하드웨어, 네트워크 케이블 링 및 더 많은 기술자의 비용을 의미한다는 것을 알고 있습니다. 그러므로, 맵디 더 적은 비용과 복잡성으로 고성능을 달성 할 수있는 기능을 제공하여 더 많은 사람들이 데이터 분석을위한 고성능 기술에 액세스 할 수 있도록합니다.

GPU 지원 덕분에 MapD도 GPU의 그래픽 기능을 활용하는 데이터 시각화 환경을 제공합니다.. 대량의 데이터가 포함 된 대화 형 그래프를 쉽게 만들 수 있으므로 거의 실시간으로 정보와 상호 작용할 수 있습니다 (모든 데이터 분석가의 꿈). 일부 기계 학습 알고리즘 (Machine Learning)을 포함하는 것 외에도 GPU를 사용하여 동일한 환경에서 고급 분석을 수행합니다.
우리는 당신이 MapD 공식 페이지 각 기능을 자세히 검토합니다. 또한 무료로 다운로드 할 수있는 문서를 제공하며 MapD를 가능하게 한 기술과 접근 방식을 자세히 설명합니다. 당신은 일부를 즐길 수도 있습니다 시민 놀라운!
MapD는 현재 베타 버전이며 Linux에서 사용 가능, 당신은 그들에게 (설명문과 함께) 편지를 써서 참여할 수 있습니다.
그런 것을 상상하지 마십시오. 처음에 그것이 나에게 이상해 보인다면 rethinkdb, 모든 것이 진보를위한 것입니다.