Saludos amigas y amigos, me da mucho gusto unirme y participar en lo que este a mi alcance de ahora en adelante en <° Desde Linux. Me llamo jathan y les comparto esta primera entrada a partir de una documentación que hice en el servicio social de la coordinación de informática de mi facultad. Espero que la encuentren interesante, les sea útil, así como hagan todo tipo de comentarios.
Når vi i en tekstfil ønsker å finne nøkkelord for opprettelse av en tematisk indeks, analysere hovedideene til et verk eller et annet lignende formål, må vi gjøre søk der vi kan skille mellom store og små bokstaver i ordene, samt en liste over disse som fremhever de ønskede tegnene, for eksempel et brev, slik at vi kan finne nøkkelord på en raskere og mer praktisk måte.
Målet med denne dokumentasjonen er å presentere og forklare bruken av en kvalitativ tekstanalyseapplikasjon og en teksteditor for å lette realiseringen av en tematisk indeks med fri programvare.
I den første delen, prosedyren for installasjon av LibreOffice og utførelsen av AntConc innenfor operativsystemet GNU / Linux og senere hvordan du gjør det i Windows og Mac OS-systemer, mens det i de følgende delene uavhengig av operativsystem vil bli forklart hvordan du bruker AntConc y LibreOffice Bruke eksempler for å lage en emneindeks.
LibreOffice og AntConc på GNU / Linux


Det første vi trenger å gjøre er å verifisere at vi har LibreOffice installert på GNU / Linux-distribusjonen. LibreOffice er en gratis kontorpakke med flere plattformer som er lisensiert med GPL, og som hjelper oss med å redigere tekstdokumenter, lysbilder, regneark, databaser, tegninger og matematiske formler på en enkel og effektiv måte.
Hvis vi bruker Debian, Linux Mint, Trisquel, Ubuntu eller annen distribusjon basert på Debian, Vi trenger ikke lenger å håndtere installasjonen siden LibreOffice i de fleste av disse distribusjonene i de nyeste versjonene, så vel som andre som Mageia, Fedora og OpenSUSE, allerede er forhåndsinstallert, og du må bare finne den og kjøre den fra applikasjonspanelet eller ved kommandolinje.
Hvis vi bruker Debian Squeeze 6.0, må vi oppdatere OpenOffice til LibreOffice ved å følge disse instruksjonene: http://www.dobleseis.com.ar/instalar-libreoffice-3-en-debian-squeeze.
Etter å ha forsikret oss om at LibreOffice er installert på systemet vårt, fortsetter vi med å besøke AntLab-nettstedet hvor vi kan finne noen nyttige applikasjoner utviklet av Laurence Anthony for kvalitativ tekstanalyse og ordmatching med kjørbare filer på tvers av plattformer for GNU / Linux, Mac OS og Windows.

AntConc er et program skrevet i Perl-programmeringsspråket som lar oss liste ord i alfabetisk rekkefølge eller etter utseendefrekvens, nøkkelord, lage samstemminger og grupper av ord fra en fil i vanlig tekstformat, og skille mellom små og store bokstaver. For å laste den ned, gå til denne lenken: http: //www.antlab.sci.waseda.ac.jp/antconc_index.html og velg i den femte kolonnen der Tux-pingvinen vises muligheten til å laste ned AntConc 3.2.4u:

Når nedlastingen av den valgte filen er ferdig, åpner vi vår foretrukne filleser (Pcmanfm, Nautilus, Thunar, Dolphin eller andre) ved å åpne den gjennom det grafiske miljøpanelet som vi bruker, eller ved å trykke på alt + f2, skrive navnet i små bokstaver og trykke enter på slutten, og opprett deretter to kataloger (mapper) i brukerkatalogen vår, og navngi en Applications_extras og en annen AntConc som en underkatalog for den første:

Nå går vi til katalogen der antconc3.2.4u.tar.gz-filen ble lastet ned (i dette eksemplet Nedlastinger), og vi åpner filen med Xarchiver eller Fileroller for å pakke ut innholdet til Antconc-katalogen ved å velge ekstraksjonsalternativet i vår filbehandling og som indikerer katalogstien / hjem / bruker / Extra_Applications / AntConc:
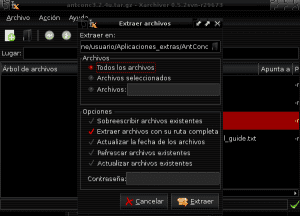
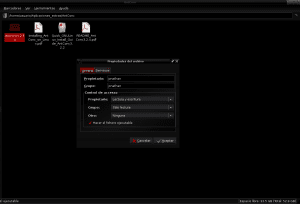
Når innholdet i antconc3.2.4u.tar.gz-pakken er ekstrahert til AntConc-katalogen i Applications_extras, identifiserer vi antconc3.2.4u-filen for å gi den utføringstillatelser ved å klikke på høyre museknapp, angi egenskaper og tillate kjøring av filen som et program:
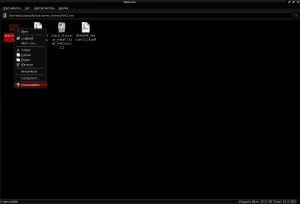
Og med dette skal vi kunne åpne AntConc ved å dobbeltklikke med musen på antconc3.2.4u-filen.
Hvis vi foretrekker det, kan vi gjøre hele den forrige prosedyren gjennom terminalen ved å utføre følgende kommandoer og endre "bruker" med navnet vi bruker i økten vår:
Slik oppretter du kataloger:
$ mkdir / home / user / Applications_extras (trykk enter)
$ mkdir / home / user / Applications_extras / AntConc (trykk enter)
Bytt til AntConc-katalogen og trekk ut innholdet i antconc3.2.4u.tar.gz:
$ cd / home / user / Applications_extras / AntConc / (trykk enter)
$ tar -xzvf /home/usuario/Descargas/antconc3.2.4u.tar.gz (trykk enter)
Tillat å kjøre antconc3.2.4u-filen som et program:
$ chmod + x antconc3.2.4u (trykk enter)
Og kjør AntConc:
$ /home/usuario/Aplicaciones_extras/AntConc/antconc3.2.4u( trykk enter)
Uansett hvilken prosedyre vi velger, kan vi kopiere antconc3.2.4u-filen til / usr / bin-katalogen og gi den de nødvendige tillatelsene for å kunne kjøre AntConc fra terminalen eller med alt + f2 ved å bare skrive antconc3.2.4u. For dette utfører vi følgende kommandoer som superbruker med su eller sudo:
$ din
(vi skriver vårt root-passord og trykker på enter)
# cp /home/user/Extras_Applications/AntConc/antconc3.2.4u / usr / bin
# chmod a + rwx /usr/bin/antconc3.2.4u
#exit
Og nå, bare ved å kjøre antconc3.2.4u med brukeren vår fra en hvilken som helst terminalemulator, vil AntConc åpne som vist i forrige bilde.
$antconc3.2.4u
Bruke AntConc til å liste opp ord etter et bestemt tegn
Etter å ha allerede identifisert hvordan du laster ned og kjører AntConc, vil vi nå vike for å eksemplifisere bruken av den for å finne noen ord ved hjelp av et søk i alfabetisk rekkefølge av tegn i både små og store bokstaver. Hvis du vil gå dypere inn i driften av AntConc og alle dens bruksmuligheter, kan du se dokumentet README_AntConc3.2.4.pdf i katalogen / home / user / Aplicaciones_extras / AntConc eller laste det ned fra http: //www.antlab .sci.waseda.ac.jp / software / antconc335 / AntConc_readme.pdf, samt konsultere den elektroniske hjelpen eller se AntConc-videoveiledningene som er tilgjengelige på nettstedet http://www.antlab.sci.waseda.ac. jp / antconc_index.html
AntConc kan bare fungere med vanlige tekstfiler (".txt"), ".html", ".hml," ".xml" og sitt eget format ".ant", så innholdet i dokumentet som vi vil lage ordidentifikasjon, vil vi endre det fra det opprinnelige formatet i ".odt", ".rtf", ".pdf" eller noe annet til ".txt" og gjøre et utvalg av alt innholdet, kopiere det og lime det inn i et nytt tekstdokument. fly som kjører vår foretrukne tekstredigerer (blant andre Leafpad, Gedit, Vim, Emacs). I dette eksemplet vil vi søke å lage en tematisk indeks fra boken «Collaborative Construction of Knowledge» som vi kan besøke nettstedet fra: http://seminario.edusol.info/seco3/ og som vi kan laste ned fritt fra denne lenken: http: / /seminario.edusol.info/seco3/pdf/seco3.pdf

Når filen er lastet ned, finner vi den i nedlastingskatalogen vår, vi åpner den med pdf-dokumentviseren vår (i dette eksemplet Evince), vi velger alt innholdet ved å trykke på ctrl + a, vi kopierer den og limer den inn i et nytt dokument med ren tekst :

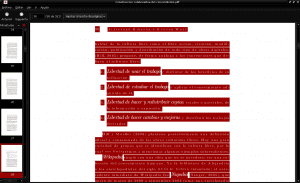
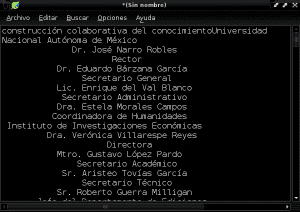
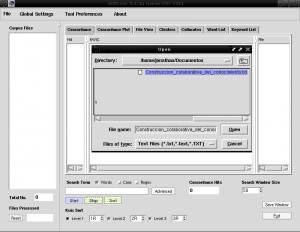
Og vi lagrer vårt nye dokument i ren tekst med navnet "Construccion_colaborativa_del_conocimiento.txt" i katalogen Dokumenter:
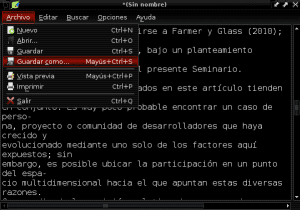
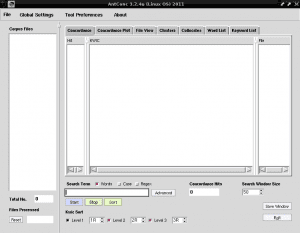
Nå kjører vi AntConc og fra den første fanen øverst til venstre kalt "File" åpner vi filen "Construccion_colaborativa_del_conocimiento.txt":
I venstre kolonne kalt "Corpus Files" vises navnet på tekstfilen vår, noe som indikerer at vi skal jobbe med denne filen, siden vi i AntConc kan laste inn mer enn en tekstfil og jobbe med dem sammen eller hver for seg:
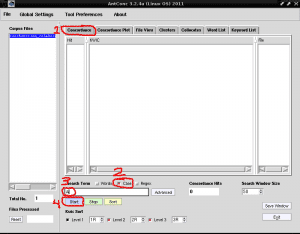
Det vi nå vil gjøre er å liste opp alle ordene som inneholder tegnet "A", for å identifisere et nøkkelord med denne store bokstaven, siden AntConc gir oss muligheten til å skille mellom store og store bokstaver, dette er veldig nyttig for å identifisere egennavn eller akronymer i listeform. For dette plasserer vi den første kategorien kalt «Concordance» på høyre side av «Corpus Files», fjerner avmerkingen for «Words» -boksen for å merke «Case» -boksen, begge nederst til høyre i «Søketerm», skriver vi i feltet Søk under bokstaven A og klikk på det lilla rektangelet som sier "Start":
Og det vil liste resultatene av det følgende. form:
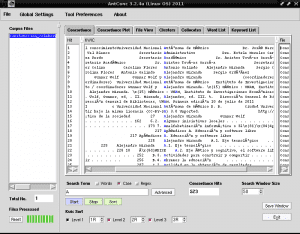
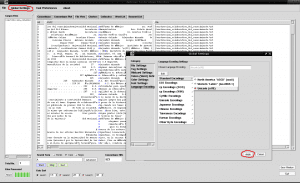
Som vi kan se, ser noen tegn skrevet med aksenter ut som ordet "Autónoma" i stedet for "Autónoma". Dette er fordi vi må fortelle AntConc det riktige kodingsspråket for språket vårt, siden AntConc ikke oppdager at vi bruker spansk som standard. For dette åpner vi fanen «Globlal Settings» øverst ved siden av «File», vi går til det siste alternativet «Language Encoding Settings» på høyre side klikker vi på «Edit» vi velger det første alternativet «Standard Encodings »Vi klikker på den, velger det tredje alternativet fra listen som vises til høyre" Unicode (utf8) "og klikker på" Bruk "-boksen nederst til høyre i vinduet:
Når du har brukt endringene, klikker du igjen på det lilla rektangelet til «Start», og de fremhevede tegnene vises nå leselig:
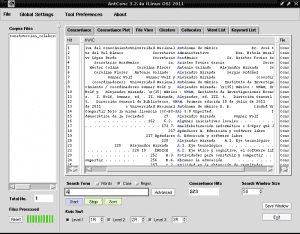
Nå vurderer vi ordene med bokstaven A uthevet i blått for enkel identifisering og basert på våre betraktninger, velger vi de som vi ønsker å ta med i den tematiske indeksen, for eksempel "Computer analfabetisme" i rad nummer 17 er det vanligste ordet. umiddelbart funnet å være den første som det er referert til i vår tematiske indeks fra innholdet i teksten til «Samarbeidskunnskapskonstruksjon».
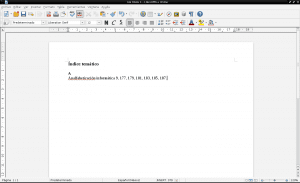
Vi går tilbake til pdf-dokumentet «Samarbeidskunnskapskonstruksjon» for å finne ut hvilke sider «Computer analfabetisme» dukker opp ved å skrive «ctrl + f», skrive ordet «Analfabetisme» i søkefeltet og trykke «enter» på slutten og antall ganger som er nødvendig for å finne det søkte ordet på alle sider. Vi åpner et nytt dokument i LibreOffice Writer for å lage emneindeksen vår, eller hvis vi jobber med innholdet i et dokument som opprinnelig er i .odt, åpner vi det dokumentet med LibreOffice, og vi oppretter og redigerer bare emneindeksen på hvilken som helst side:

Hvis vi også vil identifisere oss med AntConc i hvilke setninger "Computer analfabetisme" vises i alt innholdet i dokumentet "Construccion_colaborativa_del_conocimiento.txt", skriver vi "Computer analfabetisme" i søkefeltet, fjerner merket for "Case", merker "Words" og klikker på det å starte":
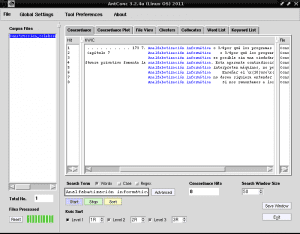
Hvis vi klikker på noen av radene som er uthevet til «Computer analfabetisme» med blå farge, for eksempel i rad 4, vil det i «File View» -fanen vise oss fragmentet av teksten der dette valget vises uthevet med svart fra bakgrunn:
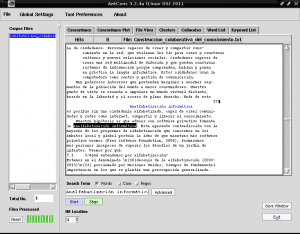
På denne måten er AntConc veldig nyttig for oss når vi har skrevet en bok, et essay eller et sammendrag, og vi ikke gjorde en tematisk indeks parallelt eller systematisk å analysere hovedideene til et verk for å gjøre det lettere å lese det.
Veldig interessant verktøy .. ..Jeg visste ikke om det .. og det er veldig nyttig for meg ..
Takk skal du ha..
veldig god artikkel, interessant
Tusen takk for at du delte
Flott bidrag, veldig nyttig. Å vite at du kan ha denne typen verktøy i Linux gjør alltid en forskjell. Hilsen.
Utmerket inngang. Jeg liker at de publiserer denne typen innhold!
Hei alle sammen. Takk for kommentarene og unnskyldning for å kunne kommentere så langt. Jeg håper at de som har praktisert veiledningen ikke har hatt noen problemer.