Witam wszystkich 🙂 Zanim przejdę dalej z tekstami listy zamówień, chcę uczcić wydanie gita 2.16, dziękując każdemu z tych, którzy wysłali łatkę oraz każdemu z użytkowników, w sumie mieliśmy około 4000 linijek między aktualizacjami i poprawkami , co nie mówi dobrze o mojej pierwszej wersji, ale mówi o Twojej dobroci 🙂 Dziękuję! Teraz powiem ci mały sekret, do tej pory nie było czasu, kiedy nie usiadłem do napisania artykułu i dużo o tym myślałem, zwykle piszę po prostu w rzędzie, a potem dobra jaszczurka przyjmuje życzliwość popraw moje błędy w pisaniu 🙂 więc też jemu dziękuję.
Nie jest to najlepsze, gdy mówimy o pisaniu artykułów, przypuszczalnie powinno to mieć cel i zbudować strukturę oraz oznaczać drobne punkty, recenzje itp. Itd. To nie tylko dotyczy blogów w ogóle, ale jest niezbędne w oprogramowanie, które udaje dobre 🙂 Do tego zadania i po kilku problemach z oprogramowaniem do kontroli wersji, które było wykorzystywane przy rozwoju jądra kilka lat temu, narodził się git 🙂
Gdzie się uczyć git?
Ilość dokumentacji na temat git jest oszałamiająca, nawet gdybyśmy wzięli tylko strony podręcznika dołączone do instalacji, mielibyśmy ogromną ilość czytania. Osobiście znajduję książka git całkiem dobrze zaprojektowane, nawet przetłumaczyłem niektóre segmenty sekcji 7, wciąż mam kilka, ale daj mi trochę czasu 😛 może w tym miesiącu uda mi się przetłumaczyć to, co zostało z tej sekcji.
Co robi git?
Git został zaprojektowany tak, aby był szybki, wydajny, prosty i obsługiwał duże ilości informacji, w końcu społeczność jądra stworzyła go dla swojego oprogramowania, które jest jednym z największych wspólnych dzieł wolnego oprogramowania na świecie i ma setki składek na godzinę w bazie kodu przekraczającej milion wierszy.
Interesującą rzeczą w git jest sposób na utrzymanie wersji danych. W przeszłości (inne programy do kontroli wersji) kompresowały wszystkie istniejące pliki w pewnym momencie historii, na przykład tworząc plik backup. Git przyjmuje inne podejście podczas wykonywania pliku commit Punkt w historii jest zaznaczony, ten punkt w historii ma szereg modyfikacji i prac, na koniec dnia wszystkie modyfikacje są gromadzone w czasie, a pliki są pobierane, aby można było skompresować lub oznaczyć jako kamienie milowe wersje. Ponieważ wiem, że to wszystko brzmi skomplikowanie, zabiorę Cię w magiczną podróż na bardzo podstawowym przykładzie.
Mały projekt obliczeniowy
Obliczenia będą programem, który znajdzie kwadraty podanej liczby, zrobimy to w C i będzie tak proste, jak to tylko możliwe, więc nie oczekuj ode mnie wielu kontroli bezpieczeństwa. Najpierw utworzymy repozytorium, zrobię to z Githubem, aby upiec dwie pieczenie na jednym ogniu:

Posiadać. Christopher Diaz Riveros
Dodaliśmy kilka dość prostych rzeczy, takich jak licencja (bardzo ważne, jeśli chcesz chronić swoją pracę, w moim przypadku zmusić ich do udostępnienia wyników, jeśli chcą użyć ich jako bazy: P)
A teraz przejdźmy do naszego drogiego terminala, git clone to polecenie odpowiedzialne za pobranie repozytorium znajdującego się w url przypisane i utworzyć lokalną kopię na naszym komputerze.
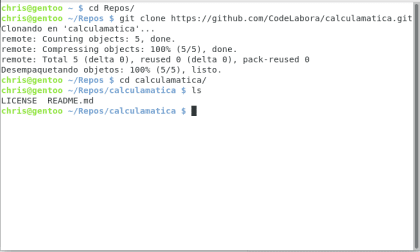
Posiadać. Christopher Diaz Riveros
Sprawdźmy teraz git log co wydarzyło się w historii naszego projektu:
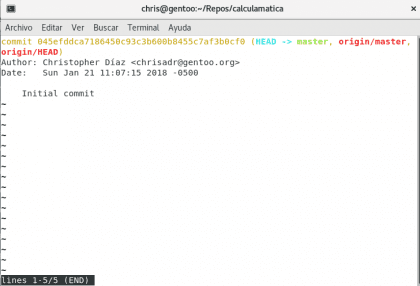
Tutaj mamy dużo informacji w różnych kolorach 🙂 spróbujmy to wyjaśnić:
pierwsza żółta linia to „kod kreskowy zatwierdzenia”, każde zatwierdzenie ma swój własny unikalny identyfikator, za pomocą którego można zrobić wiele rzeczy, ale zapiszemy go na później. Teraz mamy HEAD celeste i master Zielony. Są to „wskaźniki”, ich funkcją jest wskazanie aktualnego miejsca naszej historii (HEAD) i gałąź, nad którą pracujemy na naszym komputerze (master).
origin/master jest odpowiednikiem internetu, origin to domyślna nazwa, która została przypisana do naszego URLI master to branża, w której pracujesz ... aby to było proste, ci, którzy mają / to te, których nie ma w naszym zespole, ale są odniesieniami do tego, co jest w internecie.
Następnie mamy autora, datę i godzinę oraz podsumowanie zmiany. To jest mały przegląd tego, co wydarzyło się w tamtym momencie w historii, bardzo ważne w wielu projektach i jest wiele potępionych informacji. Przyjrzyjmy się bliżej temu, co stało się w zatwierdzeniu z poleceniem git show <código-de-commit>
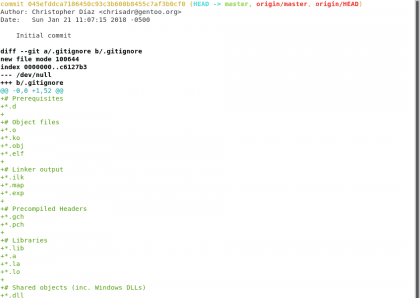
Posiadać. Christopher Diaz Riveros
Polecenie git show przenosi nas do tego ekranu w formacie łatki, gdzie można zobaczyć, co zostało dodane i co zostało usunięte (jeśli coś zostało usunięte) w tym czasie w historii, na razie pokazuje nam tylko, że dokumentacja .gitignore,README.md y LICENSE.
A teraz przejdźmy do rzeczy, napiszmy plik 🙂 stworzymy pierwszy kamień milowy w naszej historii 😀:
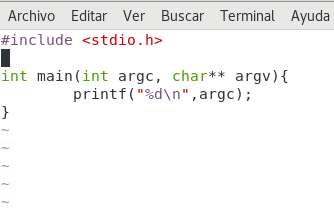
Posiadać. Christopher Diaz Riveros
Krótko mówiąc, utworzymy program, który pokaże nam liczbę argumentów przekazanych podczas jego wykonywania, proste 🙂
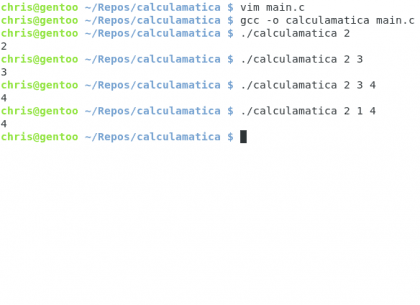
Posiadać. Christopher Diaz Riveros
To było łatwe 🙂 zobaczmy teraz następujące przydatne polecenie: git status
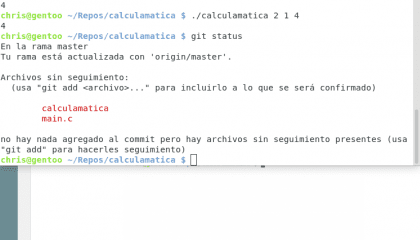
Posiadać. Christopher Diaz Riveros
Jakaś życzliwa dusza przetłumaczyła git, aby ułatwić śledzenie, tutaj mamy wiele przydatnych informacji, wiemy, że jesteśmy w gałęzi master, że jesteśmy aktualizowani origin/master(gałąź Github), mamy nieśledzone pliki! i że aby je dodać, musimy użyć git add, spróbujmy 🙂
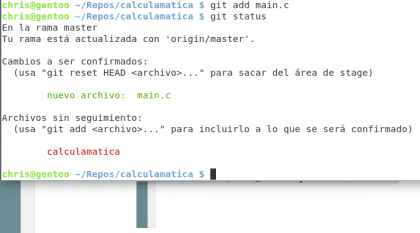
Posiadać. Christopher Diaz Riveros
Teraz mamy nową zieloną przestrzeń, w której wyświetlany jest plik, który dodaliśmy do obszaru roboczego. W tym miejscu możemy pogrupować nasze zmiany, aby dokonać zatwierdzenia, zatwierdzenie składa się z kamienia milowego w historii naszego projektu, utworzymy zatwierdzenie 🙂 git commit
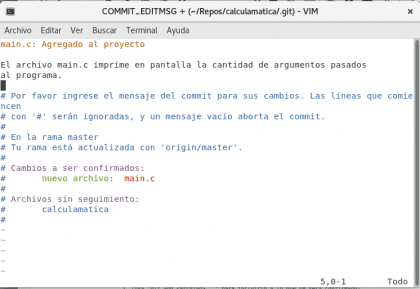
Posiadać. Christopher Diaz Riveros
Krótko mówiąc, żółta linia to tytuł naszego zatwierdzenia, piszę main.c dla zwykłego wizualnego odniesienia. Czarny tekst to wyjaśnienie zmian dokonanych od czasu poprzedniego zatwierdzenia do tej pory 🙂 zapisujemy plik i zobaczymy nasze zatwierdzenie zapisane w rejestrze.
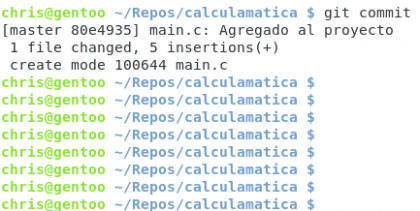
Posiadać. Christopher Diaz Riveros
Teraz zobaczymy historię naszego projektu z git log
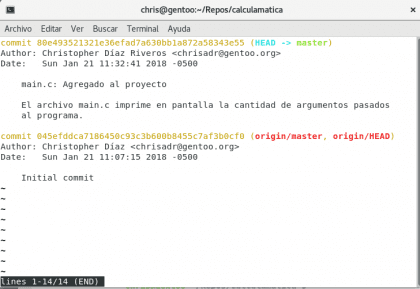
Posiadać. Christopher Diaz Riveros
Znowu w logu, teraz widzimy, że linie zielone i czerwone się różniły, to dlatego, że na naszym komputerze jesteśmy o jeden commit wyższy od tych przechowywanych w Internecie 🙂 będziemy kontynuować pracę, przypuśćmy, że teraz chcę pokazać komunikat w przypadku, gdy użytkownik umieści więcej niż jeden argument w programie (co spowodowałoby dezorientację kalkulatora 🙂)
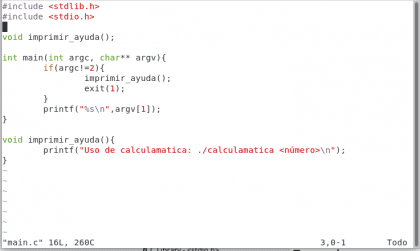
Jak widać, nasz program bardzo się rozrósł 😀, teraz mamy funkcję imprimir_ayuda() który wyświetla komunikat o tym, jak używać obliczeń oraz w bloku main() teraz robimy recenzję z if(Coś, co zobaczymy w samouczku programowania w innym czasie, na razie wystarczy wiedzieć, że jeśli do obliczeń wprowadzimy więcej niż 2 argumenty, to program się kończy i wyświetla się pomoc. Wykonajmy to:

Posiadać. Christopher Diaz Riveros
Jak widać, wyświetla teraz numer, który został dostarczony zamiast liczby argumentów, ale nie powiedziałem ci wcześniej 🙂 dla ciekawskich echo $? pokazuje kod zakończenia ostatniego wykonanego programu, którym jest 1 ponieważ zakończyło się błędem. Teraz przyjrzyjmy się naszej historii:
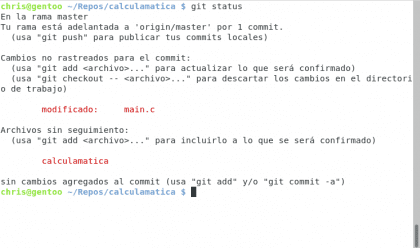
Posiadać. Christopher Diaz Riveros
Teraz wiemy, że jesteśmy o 1 zatwierdzenie przed Githubem, że plik main.c został zmodyfikowany, stwórzmy następny commit wykonując git add main.c a następnie git commit🙂

Posiadać. Christopher Diaz Riveros
Teraz jesteśmy bardziej szczegółowe, ponieważ zaimplementowaliśmy funkcję i zmieniliśmy kod walidacyjny. Teraz, gdy został zapisany, przejrzyjmy naszą ostatnią zmianę. Możemy to zobaczyć git show HEAD
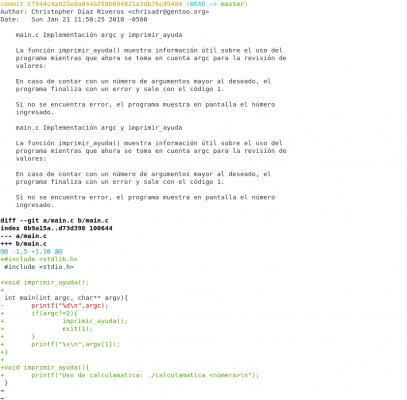
Posiadać. Christopher Diaz Riveros
Teraz możesz zobaczyć czerwone i zielone linie, dodaliśmy bibliotekę stdlib.h, zmodyfikował znaczną część kodu i dodał funkcję do naszej historii.
Teraz zobaczymy dziennik: (git log)

Posiadać. Christopher Diaz Riveros
Widzimy, że jesteśmy o dwa commity przed wersją Github, zamierzamy trochę wyrównać marker 🙂 do tego używamy git push origin master
W ten sposób mówimy, wyślij moje zatwierdzenia do adresu URL origin na gałęzi master
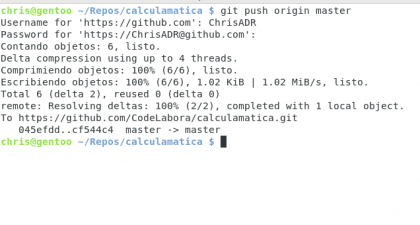
Posiadać. Christopher Diaz Riveros
Gratulacje! Teraz twoje zmiany są na Githubie, nie wierzysz mi? przejrzyjmy to 😉
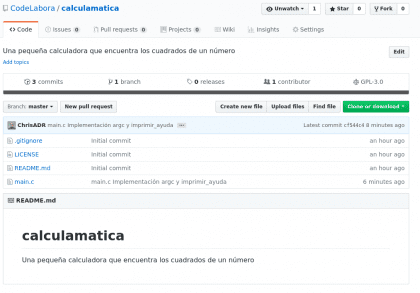
Posiadać. Christopher Diaz Riveros
Teraz mamy 3 zatwierdzenia na Github
streszczenie
Dotknęliśmy najbardziej podstawowych aspektów git, teraz mogą stworzyć prosty przepływ pracy w swoich projektach, to prawie nic z całej różnorodności rzeczy, które można zrobić za pomocą git, ale z pewnością jest to najbardziej praktyczna i codzienna rzecz dla programisty lub blogera. Nie dotarliśmy do końca kalkulatora, ale zostawimy to na inny raz 😉 Bardzo dziękuję za przybycie i mam nadzieję, że pomoże to Wam uczestniczyć w kilku projektach 😀 Pozdrowienia
Cześć ... Nie wiem, czy tak, ale nie widzę zdjęć w tym raporcie ...
pozdrowienia
To był problem z moją przeglądarką. Wstyd na irytacji.
Nadal muszę to przeczytać bardziej szczegółowo, jestem nowicjuszem.
Świetny artykuł na początek git, chociaż polecam robić notatki, aby zrozumieć szczegóły.
Kilka rzeczy nie było dla mnie jasnych:
jaka jest opcja Dodaj .gitignore CChociaż myślę, że zobaczę to, kiedy to ćwiczę,
dlaczego git add main.c musi być zrobiony ponownie przed następnym zatwierdzeniem git, czy dodanie main.c mówi gitowi, aby porównał ten plik z wersją sieciową? Czy nie porównuje automatycznie wszystkich dodanych plików do śledzenia?
Cześć Guillermo 🙂 dobrze, że znalazłeś to przydatne, aby odpowiedzieć na Twoje pytania:
.gitignore to plik, który mówi gitowi, które formaty lub wzorce mają ignorować, w tym przypadku wybranie C powoduje ignorowanie plików .o i innych, które są generowane w czasie kompilacji, co jest dobre, ponieważ w przeciwnym razie twój git oszalałby w tej chwili każdej kompilacji i uzupełnienia 🙂 możesz sprawdzić dużą liczbę formatów, które git pomija w swoim szablonie C, wykonując cat lub za pomocą edytora tekstu.
Chociaż git będzie śledził każdy plik dodany do drzewa roboczego, konieczne jest specyficzne wybranie plików, które wejdą w następne zatwierdzenie, aby dać ci przykład, załóżmy, że twoja praca doprowadziła cię do zmodyfikowania 5 różnych plików wcześniej móc zobaczyć wynik. Jeśli chcesz być bardziej szczegółowy i wyjaśnić, co jest zrobione w każdym z nich, możesz zrobić git add file1; git commit, git add plik2, git commit… .3,4,5; git commit. W ten sposób Twoja historia jest przejrzysta, a zmiany dobrze określone. A gdybyś musiał coś zmienić lub cofnąć (bardziej zaawansowane tematy), możesz cofnąć określone rzeczy lub dodać określone rzeczy bez zmiany pozostałych.
Mam nadzieję, że to pomoże 🙂 pozdrowienia i dzięki za pytanie
PS: git add nie mówi, aby porównać z wersją w sieci, ale z poprzednim zatwierdzeniem w twojej linii pracy, jeśli był lokalny (zielony), porówna go z tamtym, jeśli był zdalny (czerwony) porównać z innymi. Tylko dla wyjaśnienia 😉
Idealnie, oczywiście, wyjaśnia.