Jak mówi tytuł wpisu, ten sposób pobierania filmów z YouTube nie należy do najlepszych, ale jest to sposób na nauczenie się, jak działają programy do tego celu, takie jak te, które widzieliśmy tutaj (youtube-dl, których mają wiele możliwości i jest znakomity, polecam).
Metoda polega na użyciu typowych poleceń z programu GNU / Linux w tym celu, jakimi są curl i wiele narzędzi z bash y pyton które można wykorzystać do tworzenia skryptów. Należy zauważyć, że metoda nie jest automatyczna, ale raczej wymaga interwencji użytkownika.
Najpierw znaleźliśmy film, aby wykonać „test”.

Następnie zawartość strony uzyskujemy poprzez skrypt, który ją zapisujemy i wykonujemy w następujący sposób:
"nombre del script" "url de youtube"
przykład:
./script_url https://www.youtube.com/watch?v=1r-bWx3WZfQ
#!/bin/bash
ip=$(curl ifconfig.me)
for ((i=0;i<=10;i++))
do
curl -s $1 | grep "r$i---" | grep "expire" | grep "$ip" | grep "http" | grep "ratebypass" | grep "itag"
done
Opis skryptu:
Ustalana jest zmienna dla adresu ip, która będzie wkrótce używana, po której następuje pętla do wypróbowania różnych liczb w zmiennej „$ i”, a następnie następna linia to pobranie zawartości i filtrów słów w celu „ułatwienia” lokalizacji link, który nas interesuje.
Kiedy wykonujemy poprzedni skrypt, zwraca on następujący wynik:

Cóż, mogą pomyśleć, że to nie ma sensu, ale w rzeczywistości jest to łatwiejsze niż się wydaje. Na podstawie uzyskanych wyników wyszukujemy, wybieramy i kopiujemy rzekomy link, który jest ukryty w treści, zwykle ma on następującą postać:
http%3A%2F%2Fr2---sn-j5caxvoq5-2ute.googlevideo.com%2Fvideoplayback%3Fitag%3D5%26sver%3D3%26source%3Dyoutube%26mv%3Dm%26id%3Dd6bf9b5b1dd665f4%26ip%3D190.XXX.XX.XX%26key%3Dyt5%26upn%3DOPyez7xDXx0%26expire%3D1394709761%26sparams%3Did%252Cip%252Cipbits%252Citag%252Csource%252Cupn%252Cexpire%26ms%3Dau%26fexp%3D935640%252C927904%252C932250%252C910207%252C927860%252C916611%252C937417%252C913434%252C936910%252C936913%252C902907%252C934022%26mt%3D1394685288%26signature%3D0A96F682936F3E20015E95DC15AC3D291372CDD5.BF5B9EFF421155747A2267148C8F35B018D4A689%26ipbits%3D0
Tak naprawdę jest dużo takich linków, ale nie wszystkie z nich działają. Znalezienie go może być trochę trudne, więc do tej pracy musimy znaleźć odpowiednie słowa http, ipbity, upn, podpis a kończy się kilkoma znakami i numerami formularza BF5B9EFF421155747A2267148C8F35B018D4A689; już z tymi obiektami w rzekomym linku, kopiujemy go.
Należy zaznaczyć, że wielokrotnie link może być błędny, przynajmniej w moim przypadku musiałem to zrobić z 3 różnymi linkami, jednak działa.
Ten kod, który kopiujemy, jest w rzeczywistości adresem do zasobu (w tym przypadku jest to wideo), jednak jest zapisany w postaci znaków używanych w języku HTML, takich jak liczby zaczynające się od znaku procentu (%).
Ponieważ chcemy, aby adres był „czytelny” wpisz „http: //”, musimy przekonwertować te kody na znaki, więc zrobimy to za pomocą skryptu napisanego w pythonie:
#!/usr/bin/python
def parse_conv(dvar):
df=""
count=0
global chain
chain=""
for dc in dvar:
if dc=="%" and count==0:
count=1
elif count==1 or count==2:
df=df+dc
if count==1:
count=2
else:
count=0
chf=chr(int(df,16))
chain+=chf
df=""
else:
chain+=dc
dvar=input("Código a convertir: ")
parse_conv(dvar)
parse_conv(chain)
print(chain)
Podobnie jak w przypadku drugiego skryptu, zapisują go i uruchamiają. Pojawi się coś takiego, właśnie tam wklejają poprzedni adres i wpisują; Pojawi się adres taki jak „http: //”:
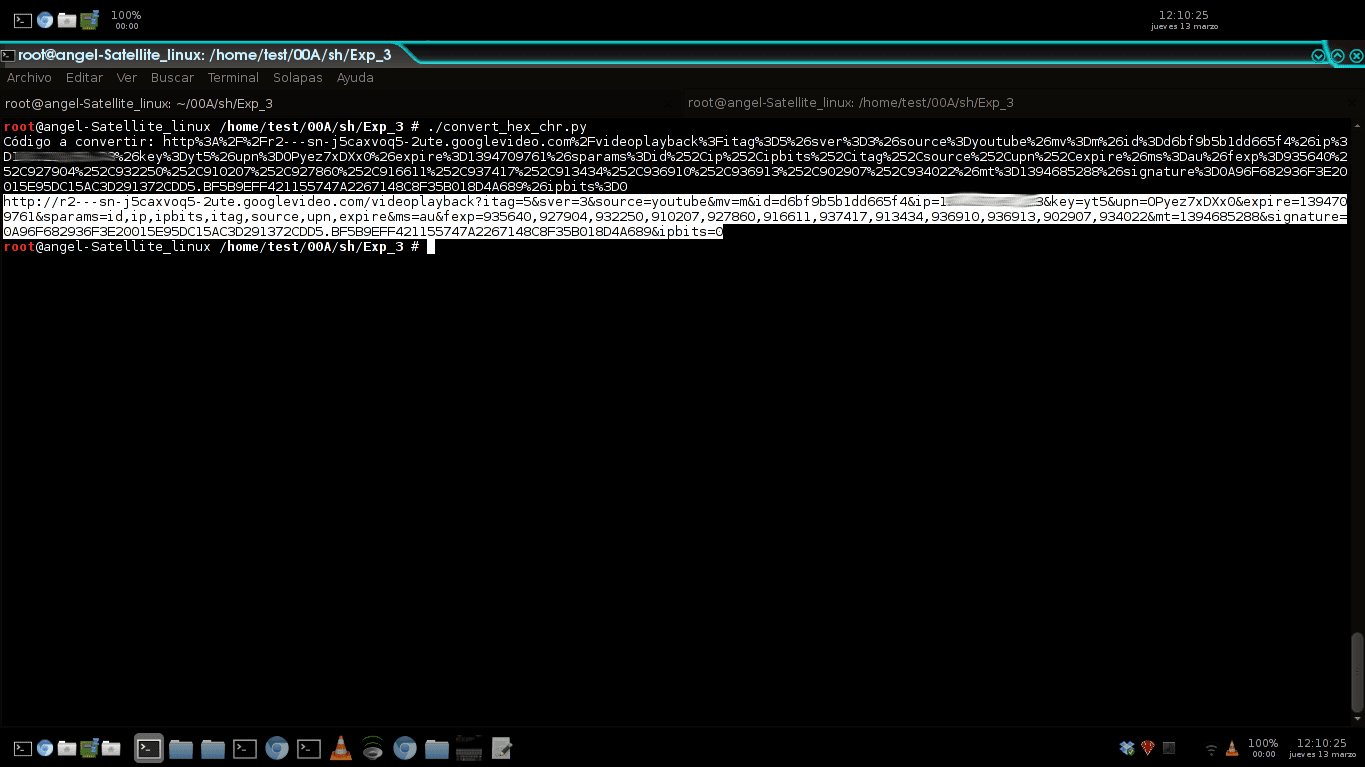
Z tego użyjemy wget aby pobrać film w następujący sposób:
wget -c "http://r2---sn-j5caxvoq5-2ute.googlevideo.com/videoplayback?itag=5&sver=3&source=youtube&mv=m&id=d6bf9b5b1dd665f4&ip=190.XXX.XX.XX&key=yt5&upn=OPyez7xDXx0&expire=1394709761&sparams=id,ip,ipbits,itag,source,upn,expire&ms=au&fexp=935640,927904,932250,910207,927860,916611,937417,913434,936910,936913,902907,934022&mt=1394685288&signature=0A96F682936F3E20015E95DC15AC3D291372CDD5.BF5B9EFF421155747A2267148C8F35B018D4A689&ipbits=0"
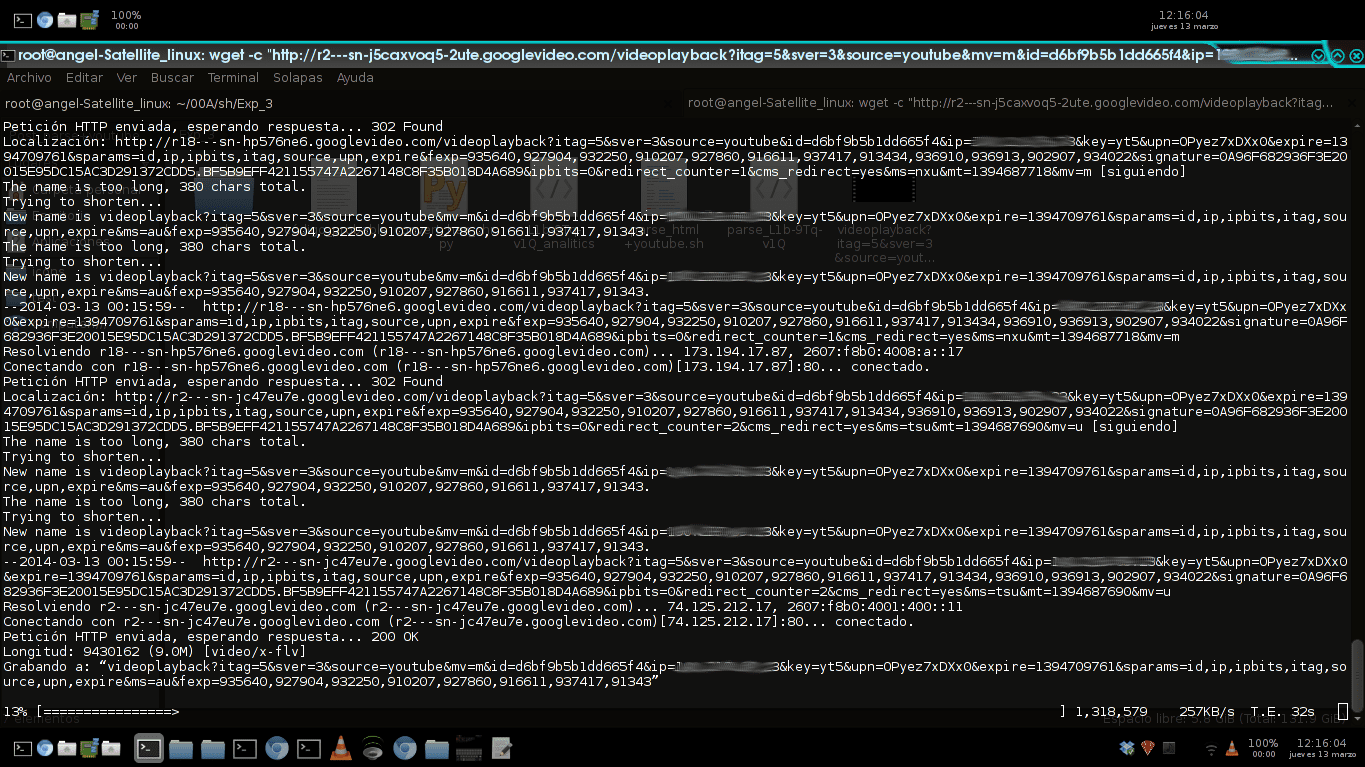
Mamy nadzieję, że to się skończy i pobierzemy nasz film z youtube pod dość dziwną nazwą:
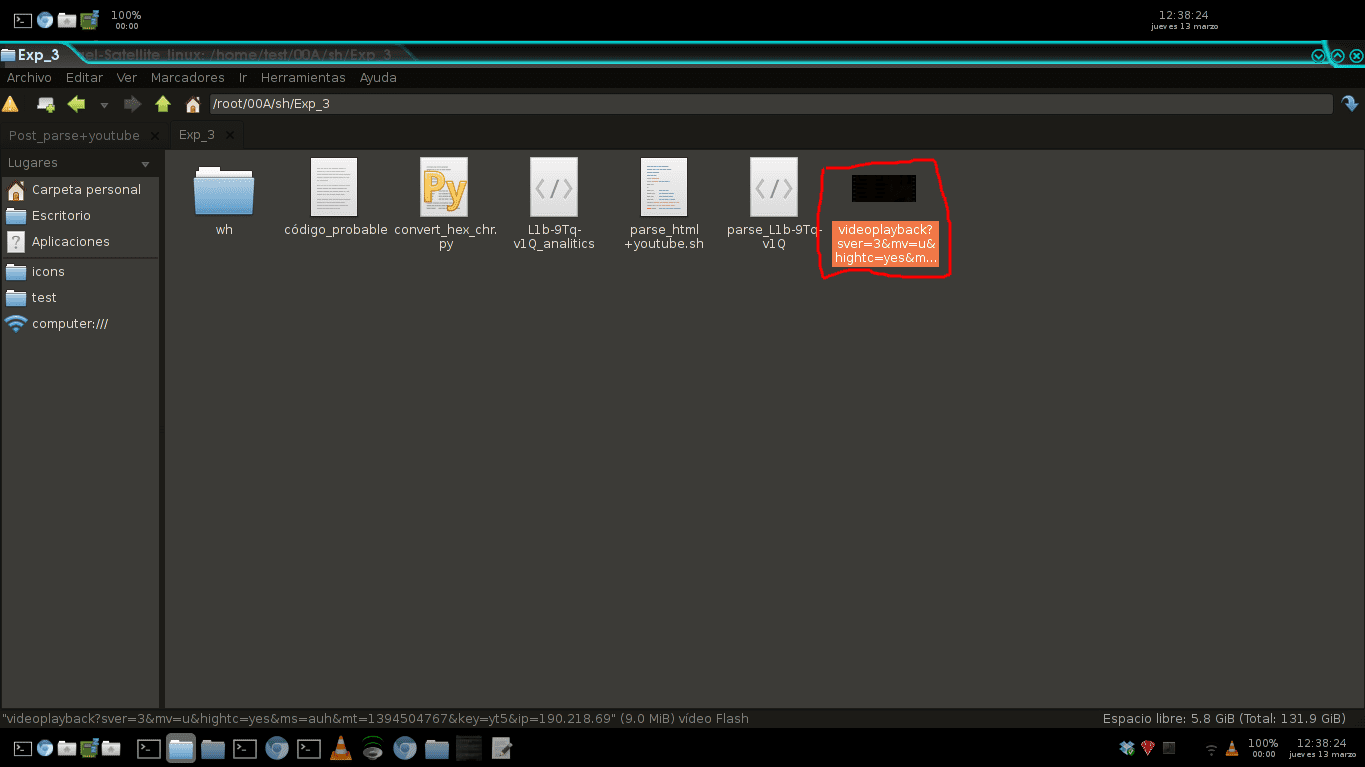
Zmieniamy jego nazwę i widzimy, że jest to ten sam film, co ten w linku, dlatego już sprawdziliśmy, że jest to trudny, ale przydatny sposób, jeśli chcesz wiedzieć, jak działa tego typu program.

Mam nadzieję, że ci to pomoże.
Dobry post, wolę prostszą metodę, wyszukuję wideo w przeglądarce, a następnie odtwarzam w terminalu:
#lsof | grep Flash
następnie kopiuję proces i daje mi plik flv
cp / proc / xxxxx / fd / xx / path / to / save.flv
to nie zadziałało dla mnie, dostaję plugin-co 25074 dla mnie mem, że mem powinien być deskryptorem pliku.
w każdym razie przy użyciu du -hL / proc / 25074 / fd / * żaden nie ma rozmiaru odpowiadającego filmowi z YouTube, czy ktoś wie, dlaczego FD się nie pojawia?
Od pół dekady używam jdownloadera do pobierania tysięcy filmów i filmów podczas nauki. Oczywiście dla tych, którzy wolą korzystać z terminala, nie jest to ważne narzędzie, poza tym, że nie jest najlżejsze (wymaga około 100 MB pamięci RAM ze wszystkim i systemem).
Nie jest najlepszy, ale istnieje rozszerzenie dla przeglądarki Firefox o nazwie Easy Youtube Video Downloader Express ...
Opuszczam ligę: https://addons.mozilla.org/es/firefox/addon/easy-youtube-video-download/
Już mnie wyciągnął z pośpiechu ... Pozdrowienia z Meksyku
Zawsze lubiłem "parsowanie" stron internetowych, jest bezsporne, że ta analiza wiedzy (sieci) + linux pozwala wyobrazić sobie małe skrypty, które robią potężne rzeczy 😀 (bot do niezłośliwych celów)
na mojej stronie umieściłem ten mały skrypt w php, który "pokazuje tylko" darmowe hasło VPN do "vpnbook", które zmienia się co jakiś czas. Mam nadzieję, że później będę wysyłać je na mój telefon komórkowy codziennie o 7 rano lub przez sms przez stronę movistar (przez innego bota): D.
strona
http://rojosbar.com/AL/1.php
Kod
http://paste.desdelinux.net/4940
możesz również uruchomić skrypt z komputera za pomocą polecenia
SKRYPT php.php
gdzie SCRIPT.php reprezentuje nazwę pliku z kodem php
-----
inny skrypt (bardzo zielony), który zrobiłem, aby pobrać "strony magazynu" z ISSUU i zapisać je w formacie PDF (ponieważ nie podoba mi się wersja flash, którą pokazują na swojej stronie internetowej)
Zobacz wideo z uruchomionym skryptem php
https://www.youtube.com/watch?v=h82r41UOWLQ
kod
http://paste.desdelinux.net/4941
youtube-dl [wideo]
po co jeszcze? proste i skuteczne 🙂
Ale gratuluję wysiłku
używam jdownloader
Tu znowu zostawiam skrypt Pythona, bo zauważyłem, że ten, który wstawiłem, nie ma zakładek.
http://paste.desdelinux.net/4942
Łatwiejszy sposób i bez programów.
1) Kliknij prawym przyciskiem myszy wideo.
2) Przejdź do „Sprawdź element”
3) Znajdź się w tagu wideo
4) Przejdź do właściwości SRC i skopiuj ten link (jeśli chcesz pominąć kroki 5 i 6, po prostu przejdź do konsoli i wpisz wget oraz skopiowany link)
5) Otwórz ten link w innej karcie
6) Kliknij prawym przyciskiem myszy -> Zapisz wideo jako ...> gotowe, ciesz się.
Świetny post, choć wydaje mi się, że może być dość dezorientujący dla widzów, którzy mogą to wykorzystać.
Już w poście widać, że istnieją lepsze sposoby pobierania filmów z YouTube. Zamierzają pokazać możliwości systemu Linux w zakresie pozyskiwania danych z sieci.
Mały przykład jako wkład:
zwijanie -s http://rss.thepiratebay.se/101 | grep magnet | link grep | sed -r "s /^.* (. +) $ / \ 1 / g" | podczas czytania linii; wykonaj echo Transmission-Remote -a $ line; Gotowe
Usuwa z portu rss piratebay wszystkie linki magnesów muzycznych, ostatnie 60, i pokazuje polecenie dodania ich do transmisji. jeśli usuniemy „echo”, doda je bezpośrednio, ostrożnie.
Wiem, że można to zrobić za pomocą Flexget lub podobnego, ale nie o to chodzi, chodzi o określenie informacji, które chcesz uzyskać z sieci i znalezienie sposobu na izolowanie ich za pomocą narzędzi, które mamy w Linuksie.
Mam nadzieję, że zbytnio się nie przedłużyłem ani nie wtrącałem.
Czy nie byłoby łatwiej korzystać z YouTube-DL?
Aby pobrać wideo:
Youtube-dl [adres URL filmu]
Aby pobrać tylko dźwięk:
youtube-dl -x –audio-format mp3 [adres URL filmu]
Dobry post, który pomaga nam lepiej zrozumieć.
Używam CLIPGRAB, a jeśli jest to konsola, używam polecenia clive lub cclive. Nie potrzebuję żadnego scenariusza 🙂
Większość z nich jest nudna uu, tak, istnieje już wiele skryptów i programów, które spełniają tę funkcję, ale przynajmniej zastanawiałeś się, jak to robią? uu ...
Cóż, nie wiedziałem w ten sposób, mam zamiar to przetestować, a mimo to podczas mojej wizyty na YouTube przez narzędzie programistyczne widziałem, że mają interfejs API (chyba REST) daje wiele informacji o filmie i dlatego link do cdn tego.
Spróbuję tego i kontynuuję z moim własnym skryptem pobierania z czymś, co zrobiłem i zrozumiałem hehe. Pozdrowienia i dobry artykuł