Uma equipe de pesquisadores de várias universidades Americanos, israelenses e australianos desenvolveu três ataques visando navegadores da web que permitem a extração de informações sobre o conteúdo do cache do processador. Um método funciona em navegadores sem JavaScripte os outros dois contornam os métodos de proteção existentes contra ataques por meio de canais de terceiros, incluindo aqueles usados no navegador Tor e no DeterFox.
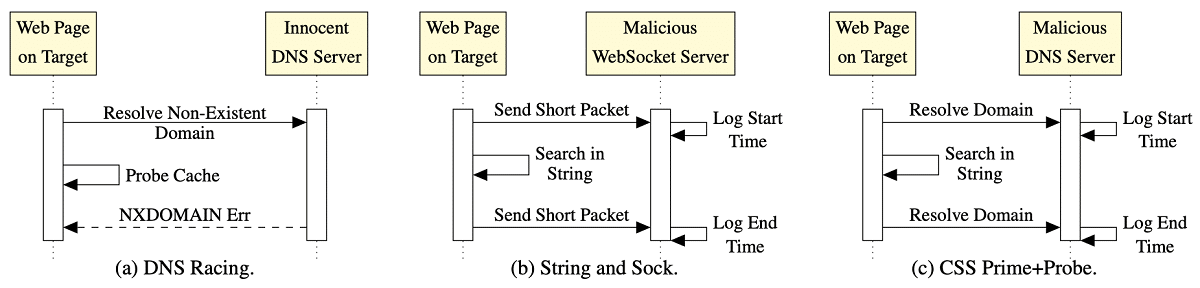
Para analisar o conteúdo do cache em todos os ataques usam o método "Prime + Probe"o que envolve preencher o cache com um conjunto de valores de referência e determinar mudanças medindo o tempo de acesso para eles quando recarregado. Para contornar os mecanismos de segurança presentes nos navegadores, que impedem a medição precisa do tempo, em duas versões é acionado um servidor DNS ou WebSocket de ataque controlado, que mantém um registro do tempo de recebimento das solicitações. Em uma modalidade, o tempo de resposta de DNS fixo é usado como uma referência de tempo.
As medições feitas em servidores DNS externos ou WebSocket, graças ao uso de um sistema de classificação baseado em aprendizado de máquina, foram suficientes para prever valores com uma precisão de 98% no cenário mais ideal (em média 80-90%). Os métodos de ataque foram testados em várias plataformas de hardware (Intel, AMD Ryzen, Apple M1, Samsung Exynos) e provaram ser versáteis.
A primeira variante do ataque DNS Racing usa uma implementação clássica do método Prime + Probe usando matrizes de JavaScript. As diferenças se resumem ao uso de um cronômetro externo baseado em DNS e um manipulador de erros que dispara ao tentar carregar uma imagem de um domínio inexistente. O temporizador externo permite ataques Prime + Probe em navegadores que restringem ou desabilitam completamente o acesso do temporizador JavaScript.
Para um servidor DNS hospedado na mesma rede Ethernet, a precisão do temporizador é estimada em cerca de 2 ms, o que é suficiente para realizar um ataque de canal lateral (para comparação: a precisão do temporizador JavaScript padrão no navegador Tor tem reduzido para 100 ms). Para o ataque, nenhum controle sobre o servidor DNS é necessário, já que o tempo de execução da operação é selecionado de forma que o tempo de resposta do DNS sirva como um sinal de uma conclusão antecipada da verificação (dependendo se o manipulador de erros foi acionado antes ou depois). , conclui-se que a operação de verificação com o cache está concluída) ...
O segundo ataque "String and Sock" é projetado para contornar as técnicas de segurança que restringem o uso de matrizes JavaScript de baixo nível. Em vez de matrizes, String e Sock usam operações de string muito grandes, cujo tamanho é escolhido de forma que a variável cubra todo o cache LLC (cache de nível superior).
Em seguida, usando a função indexOf (), uma pequena substring é pesquisada na string, que está inicialmente ausente na string original, ou seja, a operação de pesquisa resulta em uma iteração sobre toda a string. Como o tamanho da linha corresponde ao tamanho do cache LLC, a varredura permite que uma operação de verificação de cache seja realizada sem manipular matrizes. Para medir atrasos, em vez de DNS, este é um apelo a um servidor WebSocket invasor controlado pelo invasor: antes do início e após o final da operação de pesquisa, as solicitações são enviadas na cadeia,
A terceira versão do ataque "CSS PP0" via HTML e CSS, podendo funcionar em navegadores com JavaScript desabilitado. Este método se parece com "String and Sock", mas não está vinculado ao JavaScript. O ataque gera um conjunto de seletores CSS que pesquisam por máscara. A grande linha original que preenche o cache é definido pela criação de uma tag div com um nome de classe muito grande en que dentro há um conjunto de outras divs com seus próprios identificadores.
Cada um de esses divs aninhados são estilizados com um seletor que procura uma substring. Ao renderizar a página, o navegador tenta primeiro processar os divs internos, o que resulta em uma pesquisa em uma grande string. A pesquisa é feita usando uma máscara obviamente ausente e leva a uma iteração de toda a string, após a qual a condição 'não' é acionada e é feita uma tentativa de carregar a imagem de fundo.