สวัสดีเพื่อน ๆ ฉันมีความสุขมากที่ได้เข้าร่วมและมีส่วนร่วมในทุกสิ่งที่อยู่ในมือของฉันต่อจากนี้ไปใน <° Desde Linux- ฉันชื่อ Jathan และฉันแบ่งปันรายการแรกนี้กับคุณโดยอิงตามเอกสารที่ฉันทำในงานบริการสังคมของการประสานงานด้านไอทีของคณะของฉัน ฉันหวังว่าคุณจะพบว่ามันน่าสนใจ มีประโยชน์ และแสดงความคิดเห็นได้ทุกประเภท
เมื่ออยู่ในไฟล์ข้อความเราต้องการค้นหาคำสำคัญสำหรับการสร้างดัชนีเฉพาะเรื่องวิเคราะห์แนวคิดหลักของงานหรือวัตถุประสงค์อื่น ๆ ที่คล้ายคลึงกันเราจำเป็นต้องทำการค้นหาโดยวิธีที่เราสามารถแยกแยะระหว่างอักขระตัวพิมพ์ใหญ่และตัวพิมพ์เล็กภายใน คำและรายการของสิ่งเหล่านี้ที่เน้นอักขระที่ต้องการเช่นตัวอักษรเพื่อให้เราสามารถค้นหาคำหลักได้เร็วขึ้นและเป็นประโยชน์มากขึ้น
เอกสารประกอบปัจจุบันมีวัตถุประสงค์เพื่อนำเสนอและอธิบายการใช้แอปพลิเคชันการวิเคราะห์ข้อความเชิงคุณภาพและโปรแกรมแก้ไขข้อความเพื่ออำนวยความสะดวกในการสร้างดัชนีเฉพาะเรื่องด้วยซอฟต์แวร์เสรี
ในส่วนแรกขั้นตอนสำหรับการติดตั้ง LibreOffice และการดำเนินการของ แอนท์คอน ภายในระบบปฏิบัติการ GNU / Linux และวิธีการทำในระบบ Windows และ Mac OS ในภายหลังในขณะที่ในส่วนต่อไปนี้ไม่ว่าจะใช้ระบบปฏิบัติการใดจะมีการอธิบายวิธีการใช้งาน แอนท์คอน y LibreOffice การใช้ตัวอย่างเพื่อสร้างดัชนีหัวเรื่อง
LibreOffice และ AntConc บน GNU / Linux


สิ่งแรกที่เราต้องทำคือตรวจสอบว่าเราได้ติดตั้ง LibreOffice บนการแจกจ่าย GNU / Linux ของเราแล้ว LibreOffice เป็นชุดสำนักงานหลายแพลตฟอร์มฟรีที่ได้รับอนุญาตพร้อม GPL และช่วยให้เราสามารถแก้ไขเอกสารข้อความสไลด์สเปรดชีตฐานข้อมูลภาพวาดและสูตรทางคณิตศาสตร์ได้ด้วยวิธีที่ง่ายและมีประสิทธิภาพ
ถ้าเราใช้ เดเบียน, ลินุกซ์มิ้นท์, ทริสเควล, อูบุนตู หรือการแจกจ่ายอื่น ๆ ตาม debianเราจะไม่ต้องจัดการกับการติดตั้งอีกต่อไปเนื่องจากในการแจกจ่ายเหล่านี้ส่วนใหญ่ในเวอร์ชันล่าสุดรวมถึงรุ่นอื่น ๆ เช่น Mageia, Fedora และ OpenSUSE, LibreOffice ได้รับการติดตั้งไว้แล้วและคุณเพียงแค่ต้องค้นหาและเรียกใช้ จากแผงแอปพลิเคชันหรือตามบรรทัดคำสั่ง
หากเราใช้ Debian Squeeze 6.0 เราต้องอัปเดต OpenOffice เป็น LibreOffice ตามคำแนะนำเหล่านี้: http://www.dobleseis.com.ar/instalar-libreoffice-3-en-debian-squeeze
หลังจากตรวจสอบให้แน่ใจว่าเราได้ติดตั้ง LibreOffice ในระบบของเราแล้วตอนนี้เราจะไปเยี่ยมชมเว็บไซต์ AntLab ซึ่งเราสามารถค้นหาแอปพลิเคชั่นที่มีประโยชน์ที่พัฒนาโดย Laurence Anthony สำหรับการวิเคราะห์ข้อความเชิงคุณภาพและการจับคู่คำกับไฟล์ปฏิบัติการข้ามแพลตฟอร์มสำหรับ GNU / Linux, Mac OS และ Windows

AntConc เป็นแอปพลิเคชันที่เขียนด้วยภาษาโปรแกรม Perl ที่ช่วยให้เราสามารถแสดงรายการคำตามลำดับตัวอักษรหรือตามความถี่ของการปรากฏคำสำคัญสร้างความสอดคล้องและกลุ่มคำจากไฟล์ในรูปแบบข้อความธรรมดาโดยแยกความแตกต่างระหว่างอักขระตัวพิมพ์เล็กและตัวพิมพ์ใหญ่ หากต้องการดาวน์โหลดให้ไปที่ลิงค์นี้: http: //www.antlab.sci.waseda.ac.jp/antconc_index.html และเลือกในคอลัมน์ที่ห้าที่เพนกวิน Tux ปรากฏตัวเลือกเพื่อดาวน์โหลด AntConc 3.2.4u:

เมื่อการดาวน์โหลดไฟล์ที่เลือกเสร็จสิ้นเราจะเปิดเบราว์เซอร์ไฟล์ที่เราต้องการ (Pcmanfm, Nautilus, Thunar, Dolphin หรืออื่น ๆ ) โดยเปิดผ่านแผงสภาพแวดล้อมแบบกราฟิกที่เราใช้หรือโดยการกด alt + f2 เขียนชื่อลงใน ตัวพิมพ์เล็กและกดปุ่ม enter ที่ท้ายจากนั้นสร้างสองไดเร็กทอรี (โฟลเดอร์) ภายในไดเร็กทอรีผู้ใช้ของเราโดยตั้งชื่อ Applications_extras หนึ่งรายการและ AntConc อีกอันเป็นไดเร็กทอรีย่อยของไดเร็กทอรีแรก:

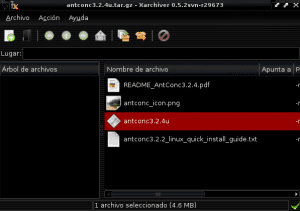
ตอนนี้เราไปที่ไดเร็กทอรีที่ดาวน์โหลดไฟล์ antconc3.2.4u.tar.gz (อยู่ในตัวอย่างนี้ดาวน์โหลด) และเราเปิดไฟล์ด้วย Xarchiver หรือ Fileroller เพื่อคลายซิปเนื้อหาไปยังไดเร็กทอรี Antconc โดยเลือกตัวเลือกแตกไฟล์ใน ตัวจัดการไฟล์และระบุเส้นทางไดเร็กทอรี / home / user / Extra_Applications / AntConc:
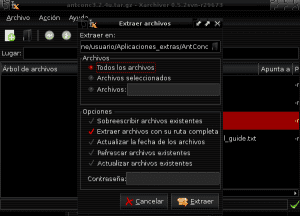
เมื่อเนื้อหาของแพ็คเกจ antconc3.2.4u.tar.gz ถูกแยกไปยังไดเร็กทอรี AntConc ภายใน Applications_extras เราจะระบุไฟล์ antconc3.2.4u เพื่อให้สิทธิ์ในการดำเนินการโดยคลิกปุ่มเมาส์ขวาป้อนคุณสมบัติและอนุญาตให้ดำเนินการ ของไฟล์เป็นโปรแกรม:
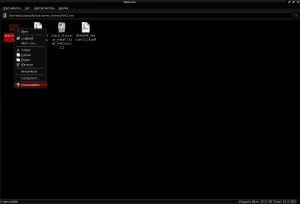
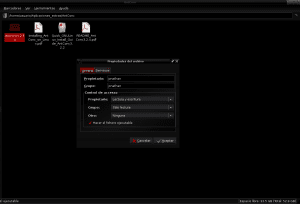
และด้วยสิ่งนี้เราควรจะสามารถเปิด AntConc ได้โดยการดับเบิลคลิกด้วยเมาส์บนไฟล์ antconc3.2.4u
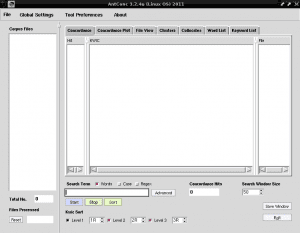
หากเราต้องการเราสามารถทำตามขั้นตอนก่อนหน้าทั้งหมดผ่านเทอร์มินัลโดยดำเนินการคำสั่งต่อไปนี้และเปลี่ยน "ผู้ใช้" ตามชื่อที่เราใช้ในเซสชันของเรา:
ในการสร้างไดเรกทอรี:
$ mkdir / home / user / Applications_extras (กด Enter)
$ mkdir / home / user / Applications_extras / AntConc (กด Enter)
เปลี่ยนเป็นไดเร็กทอรี AntConc และแตกเนื้อหาของ antconc3.2.4u.tar.gz:
$ cd / home / user / Applications_extras / AntConc / (กด Enter)
$ tar -xzvf /home/usuario/Descargas/antconc3.2.4u.tar.gz (กด Enter)
อนุญาตให้รันไฟล์ antconc3.2.4u เป็นโปรแกรม:
$ chmod + x antconc3.2.4u (กด Enter)
และเรียกใช้ AntConc:
$ /home/usuario/Aplicaciones_extras/AntConc/antconc3.2.4u (กด Enter)
ไม่ว่าเราจะเลือกขั้นตอนใดหากต้องการเราสามารถคัดลอกไฟล์ antconc3.2.4u ไปยังไดเร็กทอรี / usr / bin และให้สิทธิ์ที่จำเป็นเพื่อให้สามารถเรียกใช้ AntConc จากเทอร์มินัลหรือด้วย alt + f2 ได้โดยเพียงแค่เขียน antconc3.2.4u. สำหรับสิ่งนี้เราดำเนินการคำสั่งต่อไปนี้เป็น superuser ด้วย su หรือ sudo:
$ ของคุณ
(เราเขียนรหัสผ่านรูทของเราแล้วกด Enter)
# cp /home/user/Extras_Applications/AntConc/antconc3.2.4u / usr / bin
# chmod a + rwx /usr/bin/antconc3.2.4u
# exit
และตอนนี้เพียงแค่เรียกใช้ antconc3.2.4u กับผู้ใช้ของเราจากโปรแกรมจำลองเทอร์มินัลใด ๆ AntConc จะเปิดขึ้นตามที่แสดงในภาพก่อนหน้า
$antconc3.2.4u
ใช้ AntConc เพื่อแสดงรายการคำตามอักขระเฉพาะ
เมื่อได้ระบุวิธีดาวน์โหลดและเรียกใช้ AntConc แล้วตอนนี้เราจะยกตัวอย่างการใช้งานสำหรับการค้นหาคำบางคำโดยการค้นหาตามลำดับตัวอักษรของอักขระทั้งตัวพิมพ์เล็กและตัวพิมพ์ใหญ่ หากคุณต้องการเจาะลึกลงไปในการทำงานของ AntConc และความเป็นไปได้ในการใช้งานทั้งหมดคุณสามารถอ่านเอกสาร README_AntConc3.2.4.pdf ในไดเร็กทอรี / home / user / Aplicaciones_extras / AntConc ของเราหรือดาวน์โหลดได้จาก http: //www.antlab .sci.waseda.ac.jp / software / antconc335 / AntConc_readme.pdf ตลอดจนปรึกษาวิธีใช้ออนไลน์หรือดูวิดีโอแนะนำ AntConc ที่มีอยู่ในเว็บไซต์ http://www.antlab.sci.waseda.ac.jp/ antconc_index.html
AntConc สามารถใช้ได้เฉพาะกับไฟล์ข้อความธรรมดา (".txt"), ".html", ".hml," ".xml" และรูปแบบของตัวเอง ".ant" ดังนั้นเนื้อหาของเอกสารที่เราจะสร้าง การระบุคำเราจะส่งต่อจากรูปแบบเดิมใน ".odt", ".rtf", ".pdf" หรืออื่น ๆ ไปยัง ".txt" ทำการเลือกเนื้อหาทั้งหมดคัดลอกและวางลงในข้อความใหม่ ระนาบเอกสารที่ใช้โปรแกรมแก้ไขข้อความที่เราต้องการ (Leafpad, Gedit, Vim, Emacs และอื่น ๆ ) ในตัวอย่างนี้เราจะพยายามสร้างดัชนีเฉพาะเรื่องจากหนังสือ« Collaborative Construction of Knowledge »ซึ่งเราสามารถเยี่ยมชมเว็บไซต์: http://seminario.edusol.info/seco3/ ซึ่งเราสามารถดาวน์โหลดได้อย่างอิสระจากลิงค์นี้: http: / /seminario.edusol.info/seco3/pdf/seco3.pdf

เมื่อดาวน์โหลดไฟล์แล้วเราจะค้นหาไฟล์ในไดเร็กทอรีดาวน์โหลดของเราเราเปิดด้วยโปรแกรมดูเอกสาร pdf ของเรา (ในตัวอย่างนี้ Evince) เราเลือกเนื้อหาทั้งหมดโดยกด ctrl + a เราคัดลอกและวางลงในธรรมดาใหม่ เอกสารข้อความ:

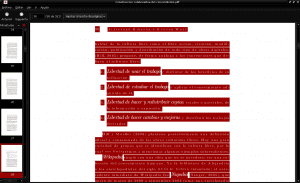
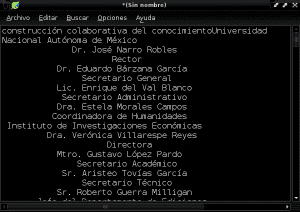
และเราบันทึกเอกสารใหม่ของเราเป็นข้อความธรรมดาด้วยชื่อ« Construccion_colaborativa_del_conocimiento.txt »ในไดเร็กทอรี Documents:
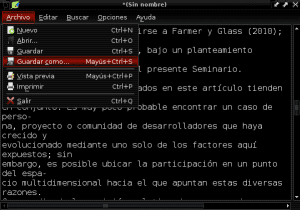
ตอนนี้เราเรียกใช้ AntConc และจากแท็บแรกทางด้านซ้ายบนที่เรียกว่า "ไฟล์" เราเปิดไฟล์ "Construccion_colaborativa_del_knowledge.txt":
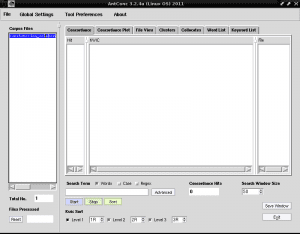
ในคอลัมน์ทางซ้ายชื่อ "Corpus Files" ชื่อของไฟล์ข้อความของเราจะปรากฏขึ้นเพื่อแสดงว่าเรากำลังดำเนินการกับไฟล์นี้เนื่องจากใน AntConc เราสามารถโหลดไฟล์ข้อความมากกว่าหนึ่งไฟล์และทำงานร่วมกันหรือแยกกัน:
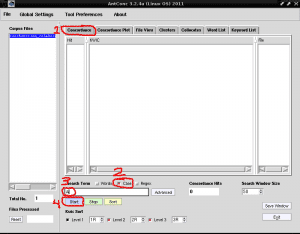
ตอนนี้สิ่งที่เราจะทำคือแสดงรายการคำทั้งหมดที่มีอักขระ "A" เพื่อระบุคีย์เวิร์ดด้วยอักษรตัวใหญ่นี้เนื่องจาก AntConc เสนอความเป็นไปได้ในการแยกแยะตัวพิมพ์เล็กและตัวพิมพ์ใหญ่สิ่งนี้มีประโยชน์มากในการระบุชื่อหรือคำย่อที่เหมาะสม ในรูปแบบรายการ สำหรับสิ่งนี้เราวางแท็บแรกชื่อว่า« Concordance »ทางด้านขวาของ« Corpus Files »ยกเลิกการเลือกช่อง« Words »เพื่อทำเครื่องหมายในช่อง« Case »ทั้งที่ด้านล่างขวาของ« Search Term »ที่เราเขียน ช่องค้นหาด้านล่างตัวอักษร A และคลิกที่สี่เหลี่ยมสีม่วงที่เขียนว่า "Start":
และจะแสดงผลลัพธ์ดังต่อไปนี้ รูปร่าง:
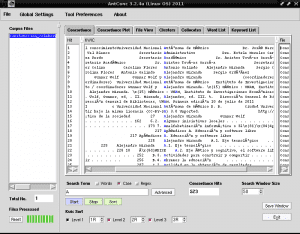
อย่างที่เราเห็นอักขระบางตัวที่เขียนโดยเน้นเสียงดูเหมือนกับคำว่า "Autónoma" แทนที่จะเป็น "Autónoma" เนื่องจากเราต้องบอก AntConc ถึงภาษาการเข้ารหัสที่เหมาะสมสำหรับภาษาของเราเนื่องจาก AntConc ตรวจไม่พบว่าเรากำลังใช้ภาษาสเปนเป็นค่าเริ่มต้น สำหรับสิ่งนี้เราเปิดแท็บ« Globlal Settings »ที่ด้านบนถัดจาก«ไฟล์»เราไปที่ตัวเลือกสุดท้าย«การตั้งค่าการเข้ารหัสภาษา»ทางด้านขวาเราคลิกที่«แก้ไข»เราเลือกตัวเลือกแรก«การเข้ารหัสมาตรฐาน»เรา คลิกที่มันเลือกตัวเลือกที่สามจากรายการที่ปรากฏทางด้านขวา "Unicode (utf8)" และคลิกที่ช่อง "ใช้" ที่ด้านล่างขวาของหน้าต่าง:
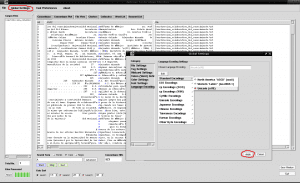
หลังจากใช้การเปลี่ยนแปลงแล้วให้คลิกอีกครั้งบนสี่เหลี่ยมผืนผ้าสีม่วงของ«เริ่ม»และตอนนี้อักขระที่เน้นเสียงจะปรากฏขึ้นอย่างชัดเจน:
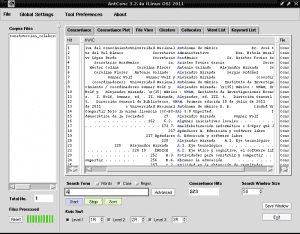
ตอนนี้เรากำลังตรวจสอบคำที่มีตัวอักษร A ไฮไลต์เป็นสีน้ำเงินเพื่อให้ระบุตัวตนได้ง่ายและจากการพิจารณาของเราเรากำลังเลือกคำที่เราต้องการรวมไว้ในดัชนีเฉพาะเรื่องตัวอย่างเช่น "การไม่รู้หนังสือคอมพิวเตอร์" ในแถวหมายเลข 17 ซึ่งเป็นคำที่พบบ่อยที่สุด พบคำในทันทีเป็นคำแรกที่ถูกอ้างถึงในดัชนีเฉพาะเรื่องของเราจากเนื้อหาของข้อความ«การสร้างความรู้ร่วมกัน»
เรากลับไปที่เอกสาร pdf «การสร้างความรู้ร่วมกัน»เพื่อค้นหาว่าหน้าใดที่ "การไม่รู้หนังสือคอมพิวเตอร์»ปรากฏขึ้นโดยการพิมพ์« ctrl + f »เขียนคำว่า«การไม่รู้หนังสือ»ในช่องค้นหาและกด« enter »ที่ท้ายและ จำนวนครั้งที่จำเป็นในการค้นหาคำที่ค้นหาในทุกหน้า เราเปิดเอกสารใหม่ใน LibreOffice Writer เพื่อสร้างดัชนีหัวเรื่องของเราหรือหากเรากำลังดำเนินการกับเนื้อหาของเอกสารที่เดิมเป็น. odt เราจะเปิดเอกสารนั้นด้วย LibreOffice และเราจะสร้างและแก้ไขเฉพาะดัชนีหัวเรื่องในหน้าใดก็ได้ :

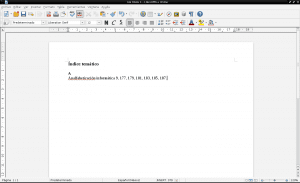
หากเราต้องการระบุด้วย AntConc ซึ่งประโยค "การไม่รู้หนังสือคอมพิวเตอร์" ปรากฏในเนื้อหาทั้งหมดของเอกสาร "Construccion_colaborativa_del_conocimiento.txt" ให้เขียน "การไม่รู้หนังสือคอมพิวเตอร์" ในช่องค้นหายกเลิกการเลือก "กรณี" ทำเครื่องหมาย "คำ" และ คลิกเพื่อ "เริ่ม":
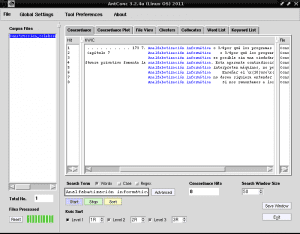
หากเราคลิกที่แถวใด ๆ ที่ไฮไลต์ไว้ที่«การไม่รู้หนังสือคอมพิวเตอร์»ด้วยสีฟ้าเช่นในแถวที่ 4 ในแท็บ«มุมมองไฟล์»จะแสดงให้เราเห็นส่วนของข้อความที่ส่วนที่เลือกนี้ถูกเน้นด้วยสีดำจากพื้นหลัง:
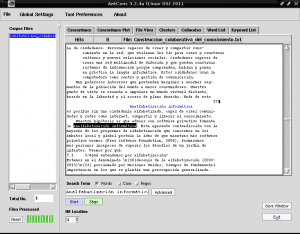
ด้วยวิธีนี้ AntConc มีประโยชน์อย่างมากสำหรับเราเมื่อเราเขียนหนังสือเรียงความหรือสรุปและเราไม่ได้ทำดัชนีเฉพาะเรื่องควบคู่กันไปหรือเพื่อวิเคราะห์แนวคิดหลักของงานอย่างเป็นระบบเพื่ออำนวยความสะดวกในการอ่าน
เครื่องมือที่น่าสนใจมาก .. .. ไม่รู้เรื่อง.. และมีประโยชน์มาก ..
ขอขอบคุณ..
บทความดีมากน่าสนใจ
ขอบคุณมากสำหรับการแบ่งปัน
ผลงานดีมีประโยชน์มาก การรู้ว่าคุณสามารถมีเครื่องมือประเภทนี้ใน Linux สร้างความแตกต่างได้เสมอ ความนับถือ.
รายการที่ยอดเยี่ยม ฉันชอบที่พวกเขาเผยแพร่เนื้อหาประเภทนี้!
สวัสดีทุกคน. ขอบคุณสำหรับความคิดเห็นและคำขอโทษที่แสดงความคิดเห็นจนถึงตอนนี้ หวังว่าผู้ที่ดำเนินการติวแล้วไม่มีปัญหาใด ๆ