朋友们大家好,我很高兴能够加入并参与从现在起<° Desde Linux。我的名字叫 Jathan,我根据我在教职员工 IT 协调的社会服务中所做的文档与您分享第一个条目。我希望您觉得它有趣、有用,并提出各种评论。
当在文本文件中我们想要找到用于创建主题索引的关键字,分析作品的主要思想或其他类似目的时,我们需要进行搜索,通过这些搜索我们可以区分主题中的大写和小写字符单词,以及这些单词的列表,突出显示所需的字符(例如字母),以便我们可以更快,更实用的方式找到关键字。
本文档旨在介绍和解释定性文本分析应用程序和文本编辑器的使用,以利于使用Free Software创建主题索引。
在第一部分中,安装程序 LibreOffice的 和执行 蚂蚁康 在操作系统内 GNU / Linux的 以及以后如何在Windows和Mac OS系统中进行操作,而在以下各部分中,无论使用哪种操作系统,都将说明如何使用 蚂蚁康 y LibreOffice的 使用示例创建主题索引。
GNU / Linux上的LibreOffice和AntConc


我们需要做的第一件事是验证我们在GNU / Linux发行版上是否安装了LibreOffice。 LibreOffice是获得GPL许可的免费的多平台办公套件,可帮助我们以简单有效的方式编辑文本文档,幻灯片,电子表格,数据库,图形和数学公式。
如果我们正在使用 Debian,LinuxMint,Trisquel,Ubuntu 或其他基于 Debian,我们将不再需要处理其安装,因为在大多数这些发行版中,包括它们的最新版本以及Mageia,Fedora和OpenSUSE等其他版本中,已经预先安装了LibreOffice,您只需找到并运行它即可从应用程序面板或通过命令行。
如果使用Debian Squeeze 6.0,则必须按照以下说明将OpenOffice更新为LibreOffice:http://www.dobleseis.com.ar/instalar-libreoffice-3-en-debian-squeeze。
确保我们已在系统上安装LibreOffice之后,我们现在将继续访问AntLab网站,在这里我们可以找到由Laurence Anthony开发的一些有用的应用程序,用于定性文本分析和与GNU / Linux,Mac跨平台可执行文件的单词匹配操作系统和Windows。

AntConc是一种用Perl编程语言编写的应用程序,它使我们能够以字母顺序或出现频率,关键字,单词的一致性和一致性以纯文本格式列出文件中的单词,以区分小写和大写字符。 要下载它,请转到以下链接:http://www.antlab.sci.waseda.ac.jp/antconc_index.html,然后在第五列中选择Tux企鹅出现的选项来下载AntConc 3.2.4u:

选定文件的下载完成后,我们通过使用的图形环境面板打开它,或按alt + f2,在其中输入其名称,从而打开首选的文件浏览器(Pcmanfm,Nautilus,Thunar,Dolphin或任何其他文件)。小写并在最后敲入Enter,然后在我们的用户目录中创建两个目录(文件夹),将一个Applications_extras和另一个AntConc命名为第一个的子目录:

现在,我们转到antconc3.2.4u.tar.gz文件的下载目录(在本示例中为Downloads),并使用Xarchiver或Fileroller打开该文件,以通过在我们的文件夹中选择extract选项将其内容解压缩到Antconc目录中。文件管理器并指示目录路径/ home / user / Extra_Applications / AntConc:
将antconc3.2.4u.tar.gz包的内容提取到Applications_extras中的AntConc目录后,我们将通过单击鼠标右键,输入属性并允许执行来标识antconc3.2.4u文件以授予其执行权限。文件作为程序:
有了这个,我们应该能够通过在antconc3.2.4u文件上双击鼠标来打开AntConc。
如果愿意,我们可以通过执行以下命令并通过在会话中使用的名称来更改“用户”,来通过终端执行所有先前的过程:
要创建目录:
$ mkdir /家庭/用户/ Applications_extras(按Enter)
$ mkdir /主页/用户/ Applications_extras / AntConc(按Enter)
转到AntConc目录,并提取antconc3.2.4u.tar.gz的内容:
$ cd /主页/用户/ Applications_extras / AntConc /(按Enter)
$ tar -xzvf /home/usuario/Descargas/antconc3.2.4u.tar.gz(按Enter)
允许将antconc3.2.4u文件作为程序运行:
$ chmod + x antconc3.2.4u(按Enter)
并运行AntConc:
$ /home/usuario/Aplicaciones_extras/AntConc/antconc3.2.4u(按Enter)
无论我们选择哪种程序,只要愿意,我们都可以将antconc3.2.4u文件复制到/ usr / bin目录,并赋予它必要的权限,使其能够从终端或通过alt + f2来运行AntConc,只需编写antconc3.2.4u。 为此,我们以超级用户身份使用su或sudo执行以下命令:
$您的
(我们输入root密码,然后按Enter键)
#cp /home/user/Extras_Applications/AntConc/antconc3.2.4u / usr / bin
#chmod a + rwx /usr/bin/antconc3.2.4u
# 出口
现在,只需通过我们的用户从任何终端仿真器上运行antconc3.2.4u,AntConc就会如上图所示打开。
$antconc3.2.4u
使用AntConc按特定字符列出单词
在已经确定了如何下载和运行AntConc之后,我们现在将通过在小写和大写字母中按字母顺序搜索字符来举例说明其用于定位某些单词的方式。 如果您想更深入地了解AntConc的操作及其所有使用可能性,可以在目录/ home / user / Aplicaciones_extras / AntConc中查阅文档README_AntConc3.2.4.pdf或从http://www.antlab下载.sci.waseda.ac.jp / software / antconc335 / AntConc_readme.pdf,以及查阅在线帮助或观看其网站http://www.antlab.sci.waseda.ac.jp/上的AntConc视频教程。 antconc_index.html
AntConc只能使用纯文本文件(“ .txt”),“。html”,“。hml”,“。xml”和其自身的格式“ .ant”,因此我们将根据该文件的内容单词识别,我们会将其从“ .odt”,“。rtf”,“。pdf”或其他形式的原始格式更改为“ .txt”,以选择所有内容,并将其复制并粘贴到新运行我们首选的文本编辑器(Leafpad,Gedit,Vim,Emacs等)的文本文档平面。 在本示例中,我们将尝试根据《知识的协作构建》一书创建一个主题索引,从中可以访问其网站:http://seminario.edusol.info/seco3/,并且可以从以下链接免费下载: http:/ /seminario.edusol.info/seco3/pdf/seco3.pdf

下载文件后,我们将其放置在我们的下载目录中,并使用pdf文档查看器(在本示例中为Evince)打开它,我们通过按ctrl + a选择所有内容,我们将其复制并粘贴到新文件中纯文本文档:

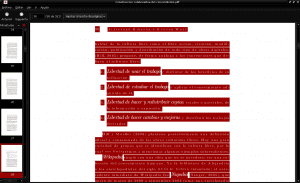
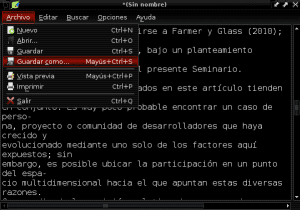
然后,将新文档以纯文本格式保存在Documents目录中,名称为«Construccion_colaborativa_del_conocimiento.txt»:
现在我们执行AntConc,并从左上角的第一个选项卡“ File”打开文件“ Construccion_colaborativa_del_conocimiento.txt”:
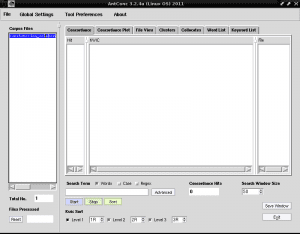
现在,在称为“ Corpus文件”的左列中,将显示我们的文本文件的名称,表明我们将在处理此文件,因为在AntConc中,我们可以加载多个文本文件,然后一起或单独处理它们:
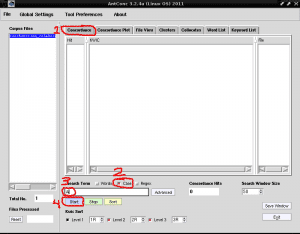
现在我们要做的是列出所有包含字符“ A”的单词,以使用大写字母标识关键字,因为AntConc为我们提供了区分小写和大写字母的可能性,这对于标识专有名称或首字母缩写词非常有用以列表形式。 为此,我们将第一个名为“ Concordance”的选项卡放置在“ Corpus Files”的右侧,我们取消选中“ Words”框以标记“ Case”框,两者都位于“ Search Term”的右下角,我们编写在字母A下方的字段中搜索,然后单击显示“开始”的紫色矩形:
它将列出以下结果。 形状:
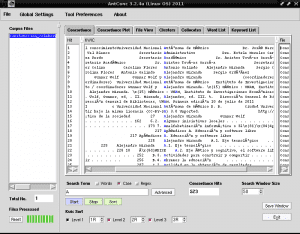
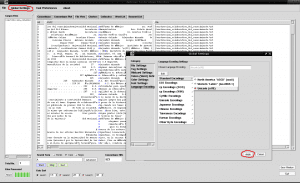
如我们所见,有些带有重音符号的字符看起来与单词“Autónoma”相似,而不是“Autónoma”。 这是因为我们必须告诉AntConc适用于我们的语言的编码语言,因为默认情况下AntConc不会检测到我们正在使用西班牙语。 为此,我们打开“文件”旁边顶部的“全局设置”选项卡,我们转到右侧的最后一个选项“语言编码设置”,我们单击“编辑”,我们选择第一个选项“标准编码”,我们单击它,从出现在右侧“ Unicode(utf8)”的列表中选择第三个选项,然后单击窗口右下方的“应用”框:
应用更改后,我们再次单击«开始»的紫色矩形,带有重音符号的字符现在将清晰显示:
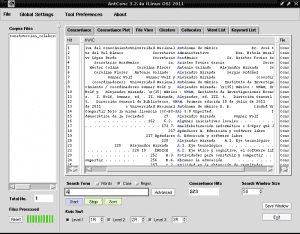
现在,我们正在审查带有蓝色突出显示的字母A的单词,以便于识别,并根据我们的考虑,我们选择要包含在主题索引中的单词,例如,最常见的第17行中的“计算机文盲”在“主题的知识的建构”文本的内容中,立即词是第一个在我们的主题索引中被提及的词。
我们返回pdf文档“知识的协作构建”,以查找“计算机文盲”出现在哪些页面,方法是键入“ ctrl + f”,在搜索栏中输入“ Illiteracy”,然后在最后按“ enter”,然后输入在所有页面上找到搜索到的单词所需的次数。 我们会在LibreOffice Writer中打开一个新文档以创建主题索引,或者如果我们正在处理原始文档为.odt的文档的内容,那么我们将使用LibreOffice打开该文档,并且我们只会在任何页面上创建和编辑其主题索引:

如果我们还想与AntConc一起在文档“ Construccion_colaborativa_del_conocimiento.txt”的所有内容中都出现“计算机文盲”一词,请在搜索字段中输入“计算机文盲”,取消选中“案例”,标记“单词”,然后单击它以“开始”:
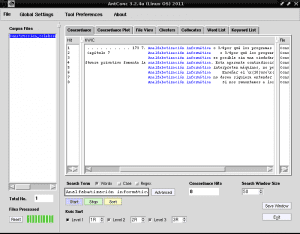
如果我们单击以蓝色突出显示为“计算机文盲”的任何行,例如在第4行的“文件视图”选项卡中,它将为我们显示该文本的片段,其中该选择显示为黑色,背景为黑色:
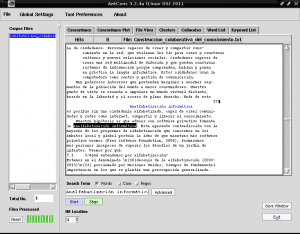
这样,当我们写书,论文或摘要并且我们没有同时做主题索引或没有系统地分析作品的主要思想以利于阅读时,AntConc对我们非常有用。
非常有趣的工具.. ..我不知道..它对我很有用..
谢谢..
很好的文章,有趣
非常感谢您的分享
贡献很大,很有用。 知道可以在Linux中拥有这些类型的工具总会有所作为。 问候。
优秀的入门。 我喜欢他们发布这类内容!
大家好。 感谢您的评论,并为能发表评论表示歉意。 我希望那些实施了补习的人没有任何问题。