Před časem jsem vám vysvětlil, jak najít a odstranit duplicitní soubory z terminálu pomocí pudinkTady vám přináším vizuální nástroj, který vám umožní udělat totéž, ale pro některé s mnohem větším komfortem.
Dupeguru
První věcí je instalace aplikace, uživatelé ArchLinuxu to mají jednoduché; jak je to v yaourt:
yaourt -S dupeguru-se
V Ubuntu musíte pro instalaci nainstalovat úložiště PPA, zde jsou všechny příkazy:
sudo apt-add-repository ppa: hsoft / ppa sudo apt-get update sudo apt-get install dupeguru-se
To bude stačit k instalaci Dupeguru.
Nyní zbývá pouze jej spustit, zobrazí se nám následující okno:

Tam můžeme přidat složky, které chceme zkontrolovat, ve kterých budou prohledány opakované soubory, například to může vypadat takto:

Pak zbývá jen kliknout na tlačítko Skenovat a voila, začne kontrolovat složky, které zadáme, zde je snímek duplicitních výsledků:
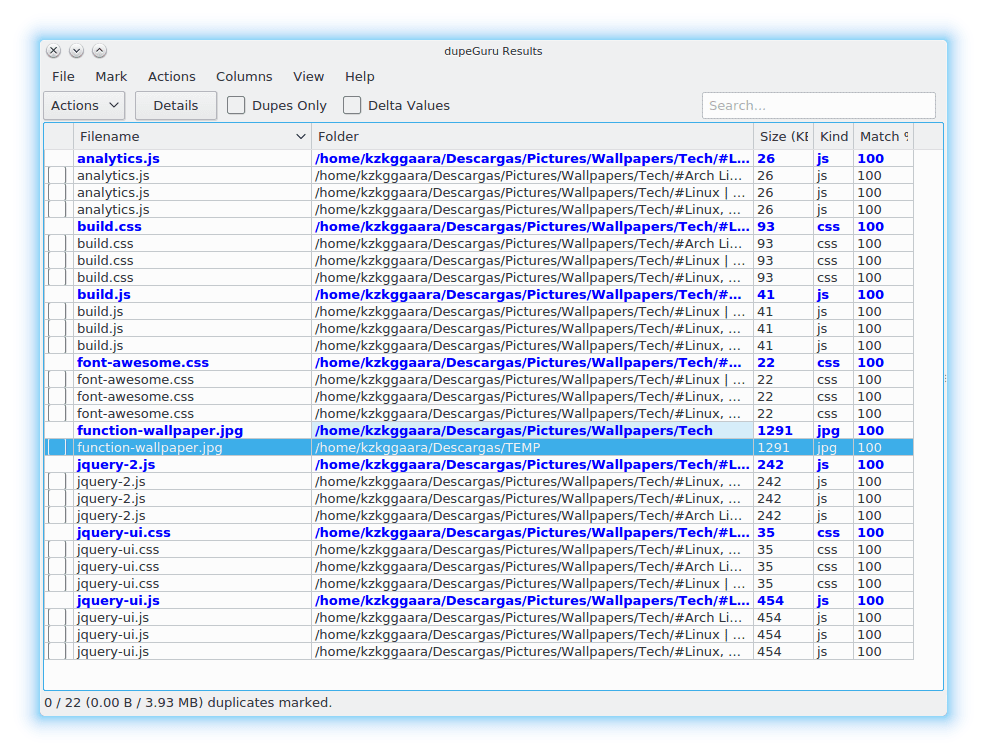
Chcete-li odstranit duplikáty, jednoduše z nabídky Akce zvolíme možnost, která nám nejlépe vyhovuje.
- Pošlete duplikáty do koše.
- Přesunout vybrané do ...
- Zkopírujte vybrané do ...
- atd atd
Možnosti DupeGuru
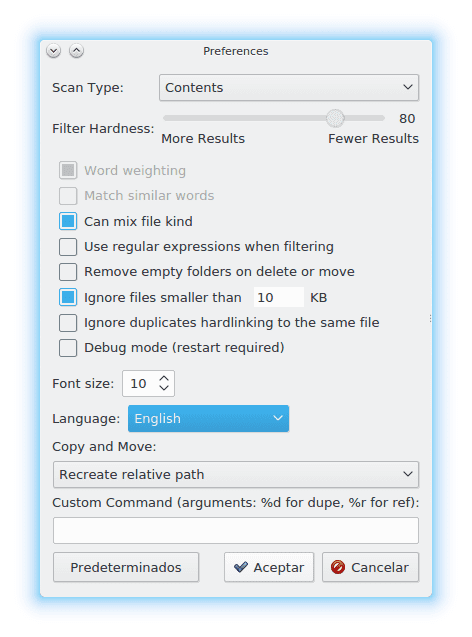
Ano dovnitř Zobrazit - »Předvolby Máme několik možností, se kterými si můžeme zahrát, způsob skenování k vyhledání duplikátů, jak přísná je aplikace k určení, zda je jeden soubor stejný jako jiný atd. Atd. Zde je snímek obrazovky s vašimi možnostmi:
Závěry DupeGuru
s DupeGuru-se V systému můžete vyhledat duplicitní soubory, což nám může na HDD ušetřit spoustu místa, ale pokud se chceme zaměřit na hudbu konkrétně s dupeguru - máme lepší možnost, protože vyhledává s přihlédnutím k tagům písně a další, podobné věci se nám stávají s obrázky, pro tyto máme dupeguru-pe ... ale hej, těmto dvěma se budu věnovat v jiném článku 😉
Prozatím již mají jinou aplikaci pro vyhledávání, vyhledávání a mazání duplicitních souborů v jejich systému.

Jaká kritéria používáte k vyhledání duplikátů? Jak vyřešíte skutečnost, že existují dva stejné soubory s různými názvy?
Váha souboru, kontrolní součet, něco takového si představuji.
Tak jako tak: http://www.hardcoded.net/dupeguru_pe/help/en/faq.html
Četl jsem komentáře v AUR a existuje uživatel, který říká, že při kompilaci v Manjaro (dupeguru-se-3.9.1) to rozpozná, jako by to byl Ubuntu…. 0_o
což dokazuje, že jde o gerunda. Děkuji
Jen minulý pátek bude existovat způsob, jak to zautomatizovat 20 tisíc duplicitních souborů a já jsem chtěl jen kopii. Pokud mi někdo dá pokyn skriptem.
Můžete použít duff: https://blog.desdelinux.net/encuentra-y-elimina-archivos-duplicados-en-tu-sistema-con-duff/
A pak jej spusťte automaticky pomocí crontab: https://blog.desdelinux.net/tag/crontab/
aah! KZKG ^ Gaara, líbí se mi, jak tvoje kde vypadá! Bude to plazma 5 s kyslíkovou tematikou?
Ehm ... je to vlastně KDE4 hahahahaha, ale díky 😀
Pozdravy. Jaký je postup jeho instalace v Debianu nebo LMDE2? Děkuji…
$ find -type f -exec md5sum '{}' ';' | třídit | uniq –všechno opakováno = oddělené -w 33 | řez -c 35-
Zdroj: commandlinefu.com
Měli byste také vyzkoušet OnlyOne, aplikaci vytvořenou v pythonu jedním z členů komunity na UCI.
Tady je odkaz.
http://humanos.uci.cu/2014/11/comparte-tu-software-onlyone-3-10-9-para-encontrar-y-gestionar-archivos-repetidos-esta-vez-para-windows-y-linux/
Děkujeme za kontrolu, ale tyto programy, jako je tento, a Fslint, který nemá skutečné grafické rozhraní, tj. S miniaturami souborů (tyto tabulky se seznamem souborů mohou mít ovládací prvky v grafickém režimu, ale ve skutečnosti zobrazují výsledky pouze v textovém režimu), protože mají řešení pro Windows, jako je Duplicate Cleaner, dělají je docela těžkopádnými a ne příliš efektivními, protože musíte soubory otevřít ručně, abyste vizuálně ověřili, že nedošlo k žádným chybám (což obvykle nikdy neměli pravdu, ale někdy se jedna objeví). Neexistuje nic se skutečným grafickým rozhraním? Pokud ne, není velký rozdíl ve srovnání s používáním příkazů konzoly, protože komentátor „msx“ označuje několik výše uvedených komentářů.
Zdravím.