Jokin aika sitten selitin sinulle kuinka löytää ja poistaa päällekkäisiä tiedostoja päätelaitteesta duffataNo, tässä tuon sinulle visuaalisen työkalun, jonka avulla voit tehdä saman, mutta joillekin paljon enemmän mukavuutta.
Dupeguru
Ensimmäinen asia on asentaa sovellus, ArchLinux-käyttäjillä on se yksinkertaista; kuten se on yaourtissa:
yaourt -S dupeguru-se
Ubuntussa sinun on lisättävä PPA-arkisto voidaksesi asentaa sen, tässä ovat kaikki komennot:
sudo apt-add-repository ppa: hsoft / ppa sudo apt-get update sudo apt-get install dupeguru-se
Tämä riittää asennukseen Dupeguru.
Nyt on vain suoritettava se, se näyttää meille seuraavan ikkunan:

Siellä voimme lisätä tarkistettavat kansiot, joissa haetaan toistuvia tiedostoja, esimerkiksi se voi näyttää tältä:

Sitten jää vain napsauttaa painiketta Skannata Ja voila, se alkaa tarkistaa määrittelemämme kansiot, tässä on kuvakaappaus kaksoiskappaleista:
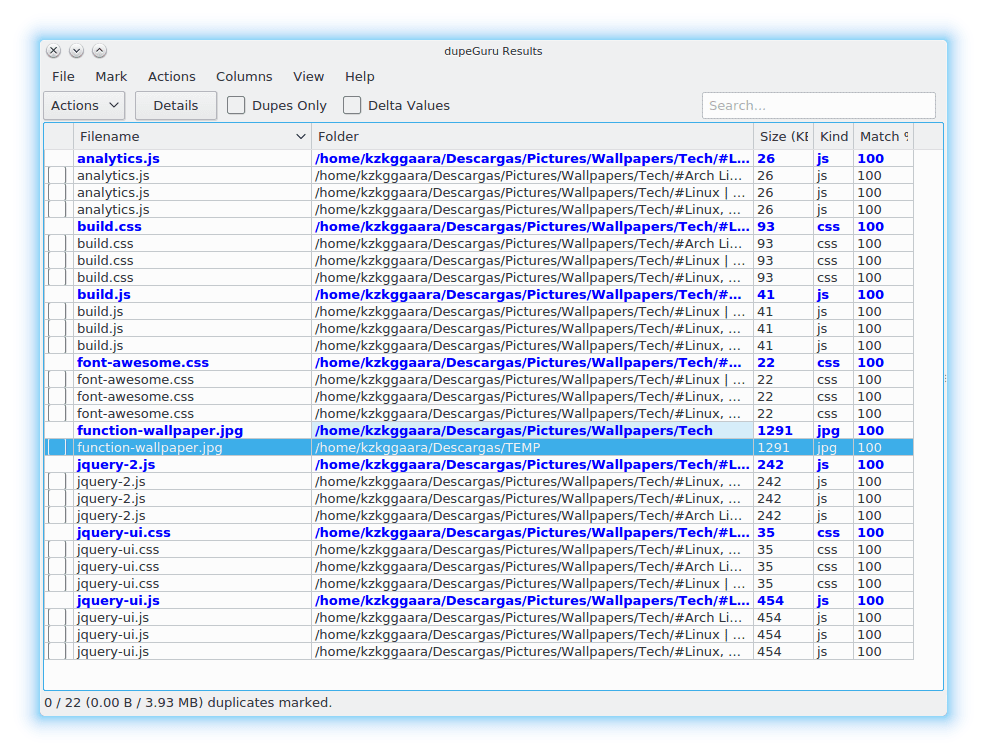
Voit poistaa kaksoiskappaleet yksinkertaisesti valikosta Toiminnot valitsemme meille parhaiten sopivan vaihtoehdon.
- Lähetä kopiot roskakoriin.
- Siirrä valitut kohteisiin ...
- Kopioi valitut kansioon ...
- jne jne
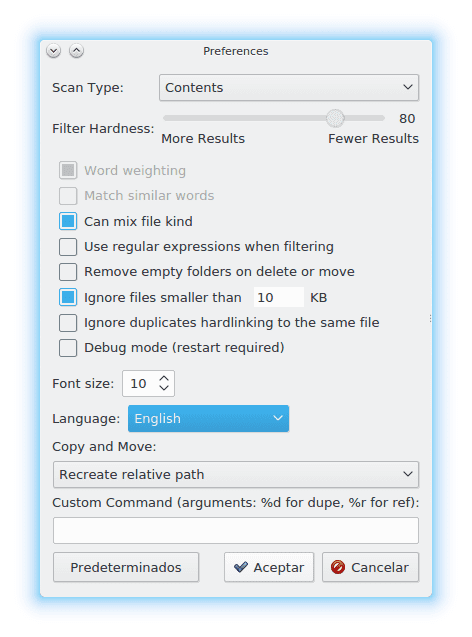
DupeGuru-asetukset
Kyllä sisään Näytä - »Asetukset Meillä on useita vaihtoehtoja, joilla voimme pelata, tapa, jolla skannaus tehdään kaksoiskappaleiden löytämiseksi, kuinka tiukka on sovellus määrittää, onko tiedosto sama kuin toinen, jne. Jne. Tässä on kuvakaappaus vaihtoehdoista:
DupeGuru-johtopäätökset
kanssa DupeGuru-se Voit etsiä päällekkäisiä tiedostoja järjestelmästä, mikä voi säästää paljon tilaa kiintolevyllä, mutta jos haluamme keskittyä musiikkiin nimenomaan dupegurulla - meillä on parempi vaihtoehto, koska se hakee ottaen huomioon kappaleita ja muita, samankaltaisia tapahtuu meille kuvien kanssa, näistä meillä on dupeguru-pe ... mutta hei, nämä kaksi muuta käsittelen toisessa artikkelissa 😉
Toistaiseksi heillä on jo toinen sovellus hakemaan, etsimään ja poistamaan kaksoiskappaleita järjestelmässään.

Mitä kriteereitä käytät kaksoiskappaleiden löytämiseen? Kuinka voit ratkaista kahden identtisen tiedoston nimen eri nimellä?
Tiedoston paino, tarkistussumma, jotain sellaista kuvittelen.
Joka tapauksessa: http://www.hardcoded.net/dupeguru_pe/help/en/faq.html
Olen lukenut AUR: n kommentteja ja on käyttäjä, joka sanoo, että Manjarossa (dupeguru-se-3.9.1) käännettynä se tunnistaa sen ikään kuin se olisi Ubuntu ... 0_o
todistaa, että se on gerundi. Kiitos
Tulee tapa automatisoida se vasta viime perjantaina TTube 20 tuhatta kopiotiedostoa ja halusin vain kopion. Jos joku neuvoo minua käsikirjoituksella.
Voit käyttää duffia: https://blog.desdelinux.net/encuentra-y-elimina-archivos-duplicados-en-tu-sistema-con-duff/
Laita se sitten ajamaan automaattisesti crontabin avulla: https://blog.desdelinux.net/tag/crontab/
aaa! KZKG ^ Gaara, rakastan miltä kde näyttää! Onko se plasma 5 happiteemalla?
Ehm ... se on oikeastaan KDE4 hahahahaha, mutta kiitos 😀
Terveiset. Miten se asennetaan Debianiin tai LMDE2: een? Kiitos…
$ find -type f -exec md5sum '{}' ';' | lajitella | uniq - kaikki toistuvat = erilliset -w 33 | leikkaus -c 35-
Lähde: commandlinefu.com
Kokeile myös OnlyOne-sovellusta, jonka yksi UCI: n yhteisön jäsen on luonut pythonissa.
Tässä on linkki.
http://humanos.uci.cu/2014/11/comparte-tu-software-onlyone-3-10-9-para-encontrar-y-gestionar-archivos-repetidos-esta-vez-para-windows-y-linux/
Kiitos tarkistuksesta, mutta nämä ohjelmat, kuten tämä ja Fslint, joilla ei ole todellista graafista käyttöliittymää eli tiedostojen pikkukuvia (näissä tiedostoluetteloita sisältävissä taulukoissa voi olla ohjausobjekteja graafisessa tilassa, mutta ne todella osoittavat johtaa vain tekstitilaan), koska niillä on Windows-ratkaisuja, kuten Duplicate Cleaner, ne tekevät niistä melko hankalia ja ei kovin tehokkaita, koska sinun on avattava tiedostot käsin varmistaaksesi, että virheitä ei ole esiintynyt koskaan ole, totuus, mutta joskus yksi ilmestyy). Eikö todellisella graafisella käyttöliittymällä ole mitään? Jos ei, ei ole suurta eroa verrattuna konsolikomentojen käyttämiseen, koska kommentoija "msx" osoittaa pari kommenttia yllä.
Tervehdys.