Salut les amis!. J'ai toujours aimé «parcourir» le référentiel. Et il y a quelque temps, j'ai trouvé un package qui peut aider beaucoup dans leur travail quotidien. Cela m'aide personnellement à trouver des articles ou des textes ou des livres, dans mon / home.
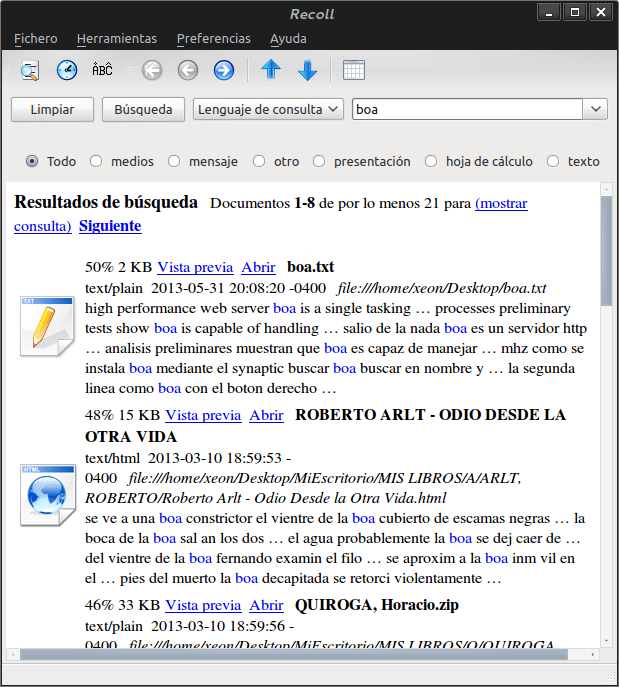
Souvenir est un outil de recherche de texte intégral (d'un mot à des expressions booléennes complexes) à l'aide d'une interface graphique conviviale, avec un minimum de technique sophistiquée et quelques dépendances externes obligatoires. Il peut fonctionner sur de nombreux systèmes d'exploitation de type UNIX et est assez indépendant de l'environnement de bureau utilisé. Il ne nécessite pas de démon comme backend pour la recherche et l'indexation. Comme utilisation des moteurs de recherche Xapian.
Pour installer Recoll, nous exécutons Synaptic, et dans la zone de texte "Filtre rapide«Nous tapons se souvenir et immédiatement il nous sera montré. Pour une utilisation normale dans Debian, il suffit d'installer ce paquet.
Ceux qui préfèrent Ubuntu peuvent également installer le package python-recoll, qui fournit un module pour étendre les fonctionnalités de Recoll et l'utiliser comme un objectif Ubuntu Unity.
Néanmoins, nous recommandons vivement aux partisans d'Ubuntu de lire l'article Recherche de presque tous les types de fichiers dans Ubuntu avec Recoll, qui m'a été envoyée par mon ami Yoandy Pérez Cáceres (Kceres de humanOS). Cet article est beaucoup plus convivial que celui-ci.
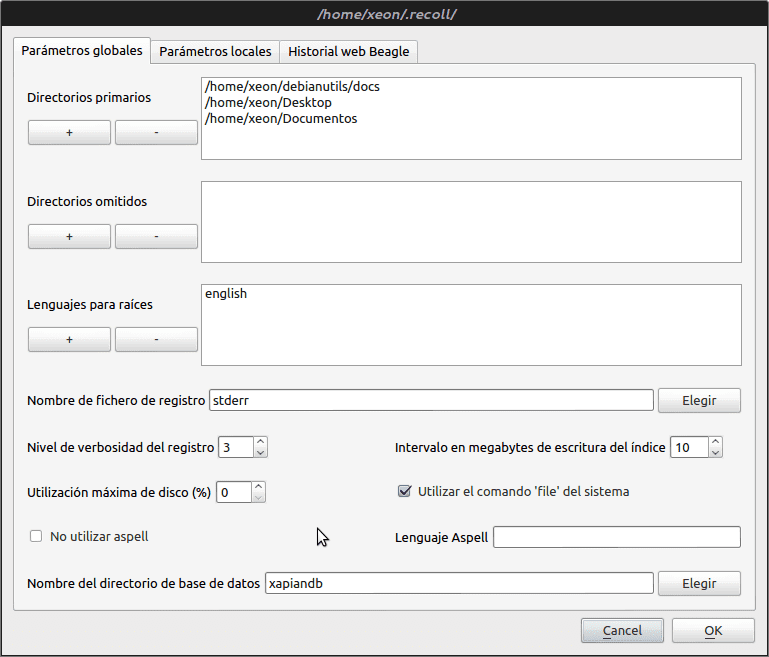
Une fois installé, nous le trouverons dans le groupe "Accessoires". Nous l'exécutons et la première chose à faire est de configurer l'indexation via l'option de menu Préférences -> Paramètres d'indexation.
Pour que la recherche ne prenne pas si longtemps et réponde à nos intérêts, nous supprimons la virgulilla ~ (cela signifie tous nos / home) des répertoires principaux et ajoutez ceux que nous jugeons nécessaires.
L'interface graphique est très intuitive et nous invitons tout le monde à découvrir les avantages de ce package. Vérifiez par vous-même la consommation de ressources achetées avec les moteurs de recherche installés par défaut avec KDE4, ou avec GNOME-Shell.
De plus, la simplicité de son installation et de son utilisation, ainsi que le très petit nombre de dépendances, le rendent idéal pour vos travaux spécifiques sur des machines de faible puissance.
Et jusqu'à la prochaine aventure, Amis !!!.
C'est donc quelque chose comme ce que fait le Nepomuk? sonne bien à utiliser avec mon openbox.
Merci pour le commentaire!. Et oui, c'est un moteur de recherche de bureau, mais avec une consommation de ressources beaucoup plus faible
Je ne pense vraiment pas que je serai à la hauteur de Nepomuk. Je vois qu'il a pas mal d'options, mais il faut voir s'il est capable d'indexer chaque élément pour ce qu'il est. Nepomuk est un énorme projet, et je ne pense pas que Recoll atteindra son niveau, du moins pas pour le moment.
nepomuk est plus lent et plus bogué que l'indexeur Windows, et cela dit déjà XD
Nepomuk n'a rien à voir avec l'indexeur Windows, ou du moins c'était aussi loin que j'étais dans Windows.
Nepomuk s'est beaucoup amélioré dans KDE 4.10 et sera beaucoup plus rapide dans KDE 4.11 😀
Ils me disent la même chose depuis 4.6 ..., ça ira mieux et bla bla bla, et je ne vois pas combien de fois j'ai été raccroché à lire ma bibliothèque de musique japonaise XD
Oui, d'après ce que j'ai compris, ils l'ont totalement changé et réécrit, il n'utilise plus strigi
Nepomuk n'affiche pas la partie du texte, encore moins la mettre en évidence, lorsque vous recherchez quelque chose. C'est supérieur !!!
Je me suis suicidé en cherchant quelque chose comme ça !!!!!
Vous ne savez pas à quel point vous m'avez rendu heureux !!!!!!!!
J'ai même essayé d'installer un certain Goonepuk (ou quelque chose comme ça) qui utilisait Nepomuk pour rechercher du texte de style Google mais cela n'a pas fonctionné.
Mais c'est idéal (de l'émotion je ne l'installe toujours pas 🙂)
Je pensais que je ne trouverais jamais quelque chose comme ça, et ça me paraît léger, idéal pour mon XFCE (dommage que ça dépende. Qt, mais on ne peut pas tout faire dans la vie, ha).
Je ne sais pas comment te remercier, tu as redonné un sens à ma vie (enfin j'exagère un peu)
MERCI BEAUCOUP!!!!!!!!!!
Merci pour votre commentaire. Je suis heureux que cela vous ait servi. Je me souviens des années 90 des programmes qu'ils utilisaient pour les recherches. Génial !!!. Maintenant, avec un programme simple, il est résolu.
Toutes nos félicitations!!!.
Si cela date des années 90, alors il est garanti qu'il sera génial, et donc bien meilleur (pour autant que je sache, la plupart des logiciels libres créés dans les années 90 étaient excellents).
Merci à tous pour vos commentaires !!! Souvenir indexe nativement le texte brut, html, maildir, mailbox (Mozilla, Thunderbird et Evolution mail), gaim, Scribus, pages de manuel et diagrammes Dia. Avec l'aide de plugins tels que iconv, xslproc, unzip, pdftotext, antiword et autres, vous pouvez également indexer Abiword, Fb2, Kword, Microsoft Office Open XML, des fichiers avec l'extension SVG, Gnumeric, Okular, pdf, MS Word, Wordperfect , Lyx, Powerpoint, Excel, fichiers CHM. Il peut également servir de complément à Firefox pour indexer l'historique des pages web, ou le traitement des pièces jointes des emails.
Je ne connais pas la portée des autres moteurs de recherche, mais pour mes besoins, les avantages sont nombreux. 🙂
Eh bien, dans Windows 7, il peut être trouvé dans des fichiers docx si je ne suis pas confus. Mais je suis vraiment confus. Mais s'il prend en charge odt, cela doit être prouvé.
Bien, mais les résultats sont différents.
Je ne me lasse pas de bien parler de ce programme. J'utilise un environnement gtk et pour la même raison, je pourrais chercher une solution qui utilise des bibliothèques de cette famille, mais l'alternative prétendument puissante de gtk, tracker, est terrible. En ce qui concerne Nepomuk, il est fou de l'installer si vous n'utilisez pas KDE (en fait, cela n'a pas de sens de le faire), car son installation contient presque tout KDE. De plus, je l'ai testé nativement dans un environnement KDE et la vérité est qu'il ne me convainc pas, ni par les performances ni par les résultats. Recoll prend peu de ressources, indexe parfaitement et montre les résultats d'une manière très utile. Pour l'instant, je ne change rien à cet outil.
Salutations.
Merci pour le commentaire!!!. Le souvenir correspond, et de loin, à mes besoins. Le moteur Xapian - ou ses bibliothèques - est utilisé dans d'autres applications telles que Synaptic et vous ne savez même pas quand vous indexez.
Une question: quel environnement de bureau utilisez-vous et quel thème utilisez-vous? Parce que le thème que vous avez utilisé dans GNOME 3 dans le didacticiel QEMU-KVM était vraiment cool.
si je ne me trompe pas, je suppose que c'est XFCE avec le thème Albatross (le meilleur de tous)
@ eliotime3000, @gato: Salutations tout d'abord. Après avoir utilisé Cinnamon pendant quelques semaines, je suis retourné à GNOME-Shell. Oui au Shell critiqué. Et cela vous paraîtra étrange, mais comme je l'ai dit dans la 1ère partie du QEMU-KVM, pour moi c'est une balle. Vous savez quoi? Je me suis le mieux adapté et je ne suis pas du tout jeune. 🙂 J'ai les extensions gnome-shell-classic-systray_0.1-0+20120306~webupd8~precise1_all.deb et la gnome-shell-frippery-0.4.1.tar.gz et la vérité est que je ne manque presque rien dans GNOME 2. Le fichier tar, gz, contient 6 extensions qui doivent être copiées dans ~ / .local / share / gnome-shell / extensions /, redémarrez le GDM3, puis avec le gnome-tweak-outil définir l'environnement. Et @gato, si j'utilise le Albatros, qui est installé avec le package shiki-thème-humain et ses dépendances.
Quoi qu'il en soit, je me suis habitué au GNOME-Shell et je le recommande à tout le monde. Cela pourrait m'exciter et publier un article, en particulier pour les nouveaux arrivants, sur la façon de créer un bureau Debian personnalisé.
Excellent outil!
Elle est très bonne. La création de la base de données prend un certain temps, mais la recherche est très rapide.
Il recherche même des mots dans les fichiers LibreOffice et Inkscape (.svg). C'est très utile lorsque nous ne connaissons pas le nom d'un fichier mais que nous connaissons une partie du contenu. Je vous remercie!
Merci d'avoir commenté, Joaquín !!!. Le temps nécessaire à la création de la base de données dépend du nombre de dossiers que vous avez déclarés dans la configuration. Cependant, je ne sais pas si vous avez vérifié que lors de l'indexation et de la création de la base de données, vous pouvez travailler normalement.
homme grep
Et si vous utilisez Ubuntu, il existe un objectif qui rend sa manipulation la chose la plus facile au monde.
Au fait, pour l'installer dans Ubuntu, ce que vous devez faire est d'installer les packages recoll (pour le programme) et recoll-lens (pour l'objectif).
Dans l'article que j'ai référencé ci-dessus, "Recherche de presque tous les types de fichiers dans Ubuntu avec Recoll", une explication détaillée de la façon d'installer Recoll dans Ubuntu est donnée. Merci pour le commentaire!!!.
Salut,
Je suis informaticien et je travaille à la mairie de Coria (Cáceres). Nous implémentons Ubuntu et, entre autres utilitaires, nous utilisons Recoll.
Ce que je veux savoir, c'est comment vous avez obtenu la version espagnole.
Salutations et remerciements.
Je pense que je me suis répondu.
Dans les référentiels Ubuntu, il y a la version 1.17.3 et la traduction espagnole a été introduite dans la version 1.19.3
Salutations.
Salutations Angel !!!. Eh bien, dans Debian 7 "Wheezy", la version est 1.17-3.2, et elle est traduite. Apparemment, les debianeros l'ont empaqueté à partir d'une version traduite en espagnol afin qu'il puisse être utilisé si nécessaire. Je pense que vous pouvez en télécharger un sur le site Web Debian.
Je viens de découvrir une option spectaculaire. Recoll peut être fait pour indexer des fichiers sans avoir besoin de se connecter ou d'avoir une interface graphique active.
Il peut être exécuté automatiquement avec la commande recollindex -x -m. Le -x est pour qu'il fonctionne sans interface graphique active (sans les X) et le -m est pour qu'il surveille les fichiers en temps réel (quand on est créé ou modifié). De plus, vous pouvez modifier le fichier de configuration recoll.conf, qui se trouve généralement dans le dossier home .recoll pour vous indiquer les dossiers à surveiller, etc.
Tout cela est idéal pour indexer des fichiers sur un serveur par exemple.
Ensuite, à l'intérieur de l'interface graphique, vous pouvez lui faire utiliser des index externes lors de la recherche (dans les préférences -> paramètres d'index externe).
J'ai également créé un petit script pour init.d pour que l'indexeur démarre automatiquement au démarrage du serveur.
Et donc depuis les bureaux, je peux rechercher les fichiers indexés sur le serveur.
Cracking
Incroyable contribution, ami Andrés Sánchez !!!. Je vais en tenir compte pour l'appliquer sur mes serveurs de fichiers avec Samba. Merci pour le détail du partage de votre découverte.
Salutations de Federico
De rien monsieur. C'est de cela qu'il s'agit, partager nos découvertes.
Au fait, jetez un œil à l'aide pour configurer le fichier recoll.conf. Vous pouvez modifier les itinéraires d'indexation (par défaut, il ne le fait qu'à la maison), omettre les fichiers et les dossiers dans ces itinéraires, spécifier s'il faut suivre les liens symboliques, spécifier les langues (langues) qui seront utilisées pour l'indexation, l'encodage du fichiers, si l'indexation est sensible à la casse, le chemin où l'index sera enregistré (c'est idéal pour accéder ultérieurement à l'index à partir d'un autre ordinateur, tant que le chemin de l'index est dans un dossier partagé) et de nombreuses autres options que je n'ai pas encore a tenté.
Dans le chemin / usr / share / recoll / examples (au moins dans ubuntu), il y a des fichiers d'exemple de la configuration.
Bonjour, je suis un utilisateur d'OpenSuse (aujourd'hui version 13.1) et en tant qu'outil d'indexation, j'utilise Google Desktop depuis des années! (J'ai lu les problèmes qu'il a et les failles de sécurité, blablablabla,) mais jusqu'à présent je n'avais pas vu ou trouvé quelque chose qui soit à son comble par rapport aux résultats.
J'utilise Recoll depuis moins d'un mois et comme il est si complet, il ne fonctionne plus pour moi. Il est complexe à configurer, il n'est pas destiné à l'utilisateur ordinaire qui ne comprend pas grand-chose aux commandes et aux trucs.
Cela semble très prometteur mais pour l'instant je ne suis pas entièrement convaincu.
Si quelqu'un peut me donner un coup de main avec un petit problème (je dirais la Flandre).
Lors de son installation, avant la première indexation personnelle, j'ai décidé d'ajouter plusieurs répertoires distants et système (/ usr / share, etc, / mnt / répertoire réseau interne, / mnt / my disk lacie pour la sauvegarde,)
Le problème que j'ai trouvé est que lorsque j'entre un texte pour une recherche simple, il renvoie en conséquence, d'abord ceux qui sont dans mes répertoires externes ("/ mnt /….") Et enfin ceux qui sont dans / home / mon nom.
Un autre problème est que lorsque j'entre comme recherche "DNI mon nom" (sans guillemets), il ne renvoie aucun résultat si je choisis le filtre "nom de fichier" alors que le fichier s'appelle simplement "DNI mon nom.jpg"
Pour que le fichier apparaisse, je dois choisir "tous les termes ou tout terme"
Jusqu'à présent, pour des raisons pratiques, de rapidité et de simplicité, le bureau de Google est toujours le meilleur, à moins que je ne trouve comment configurer le Recoll et comment lui donner la priorité des fichiers chez moi lors du renvoi des résultats.
Si quelqu'un peut m'aider ou me dire où je peux trouver un guide simple (PAS LE MANUEL de la page 50MIL et il est en anglais)
Merci beaucoup pour la publication. TRÈS BON.
PS: Nepomuk ne m'a jamais servi du tout !! Je n'ai jamais vu comment en extraire le jus et comment cela fonctionne. Ils disent partout à quel point c'est bon mais je n'ai jamais vu personne comment en tirer le meilleur parti et comment le mettre en pratique