नमस्कार दोस्तों, अब से <° में जो कुछ भी मेरी पहुंच में है, उसमें शामिल होने और भाग लेने में मुझे बहुत खुशी हो रही है Desde Linux. मेरा नाम जथन है और मैं अपने संकाय के आईटी समन्वय की सामाजिक सेवा में किए गए दस्तावेज़ीकरण पर आधारित यह पहली प्रविष्टि आपके साथ साझा कर रहा हूँ। मुझे आशा है कि आपको यह रोचक, उपयोगी लगेगा और आप सभी प्रकार की टिप्पणियाँ करेंगे।
जब एक पाठ फ़ाइल में हम एक विषयगत सूचकांक के निर्माण के लिए कीवर्ड ढूंढना चाहते हैं, किसी कार्य के मुख्य विचारों या किसी अन्य समान उद्देश्य का विश्लेषण करते हैं, तो हमें उन साधनों द्वारा खोज करने की आवश्यकता होती है, जिनमें हम अपरकेस और लोअरकेस वर्णों के बीच अंतर कर सकते हैं। शब्द, साथ ही इनमें से एक वर्ण जैसे वांछित वर्णों को उजागर करने की एक सूची है ताकि हम कीवर्ड को तेज और अधिक व्यावहारिक तरीके से पा सकें।
इस दस्तावेज़ का उद्देश्य एक गुणात्मक पाठात्मक विश्लेषण अनुप्रयोग और एक पाठ संपादक के उपयोग को मुफ्त सॉफ्टवेयर के साथ विषयगत सूचकांक की प्राप्ति की सुविधा के लिए प्रस्तुत करना और व्याख्या करना है।
पहला भाग स्थापित करने की प्रक्रिया की व्याख्या करेगा लिब्रे ऑफिस और का निष्पादन एंटकोनक ऑपरेटिंग सिस्टम के भीतर ग्नू / लिनक्स और बाद में इसे विंडोज और मैक ओएस सिस्टम में कैसे किया जाता है, जबकि ऑपरेटिंग सिस्टम की परवाह किए बिना निम्नलिखित भागों में, यह समझाया जाएगा कि कैसे उपयोग करें एंटकोनक y लिब्रे ऑफिस विषय सूचकांक बनाने के लिए उदाहरणों का उपयोग करना।
जीएनयू / लिनक्स पर लिब्रे ऑफिस और एंटकॉन


पहली चीज़ जो हमें करने की ज़रूरत है वह यह है कि हमारे GNU / Linux वितरण पर लिबरऑफिस स्थापित हो। लिब्रे ऑफिस एक नि: शुल्क मल्टीप्लायर है, जो जीपीएल के साथ लाइसेंस प्राप्त है और यह हमें सरल और कुशल तरीके से टेक्स्ट डॉक्यूमेंट, स्लाइड, स्प्रेडशीट, डेटाबेस, ड्रॉइंग और गणितीय फॉर्मूले संपादित करने में मदद करता है।
अगर हम उपयोग कर रहे हैं डेबियन, लिनक्समिंट, ट्रिसक्वेल, उबंटू या किसी अन्य वितरण के आधार पर डेबियन, अब हमें इसके इंस्टॉलेशन से निपटने की जरूरत नहीं होगी क्योंकि इन वितरणों में से अधिकांश अपने हाल के संस्करणों में और साथ ही साथ मागिया, फेडोरा और ओपनसैस, लिब्रे ऑफिस में पहले से ही स्थापित हैं और आपको बस इसे ढूंढना है और चलाना है यह एप्लिकेशन पैनल से या कमांड लाइन से।
अगर हम डेबियन स्क्वीज़ 6.0 का उपयोग कर रहे हैं तो हमें इन निर्देशों का पालन करते हुए ओपनऑफिस को लिब्रे ऑफिस में अपडेट करना होगा: http://www.dobleseis.com.ar/instalar-libreoffice-3-en-debian-seeeeze।
यह सुनिश्चित करने के बाद कि हमारे पास लिबरऑफिस हमारे सिस्टम पर स्थापित है, हम अब एंटलैब वेबसाइट पर जाएँगे जहाँ हम लॉरेंस एंथोनी द्वारा विकसित कुछ उपयोगी अनुप्रयोगों को गुणात्मक पाठ विश्लेषण और जीएनडीयू / लिनक्स, मैक के लिए क्रॉस-प्लेटफ़ॉर्म निष्पादन योग्य फ़ाइलों के साथ मेल खाते हुए पा सकते हैं। ओएस और विंडोज।

AntConc पर्ल प्रोग्रामिंग भाषा में लिखा गया एक एप्लिकेशन है जो हमें वर्णमाला क्रम में शब्दों को सूचीबद्ध करने या उपस्थिति की आवृत्ति, कीवर्ड, मैच और शब्दों के समूहों को सादे पाठ प्रारूप में एक फाइल से बनाने में मदद करता है, जो लोअरकेस और अपरकेस अक्षरों के बीच अंतर करता है। इसे डाउनलोड करने के लिए, इस लिंक पर जाएं: http: //www.antlab.sci.waseda.ac.jp/antconc_index.html और पांचवें कॉलम में सेलेक्ट करें जहां Tux पेंगुइन एंटीकॉक 3.2.4u डाउनलोड करने का विकल्प दिखता है:

जब चयनित फ़ाइल का डाउनलोड समाप्त हो जाता है, तो हम अपने पसंदीदा फ़ाइल ब्राउज़र (Pcmanfm, Nautilus, Thunar, Dolphin या किसी भी अन्य) को ग्राफिकल पर्यावरण पैनल के माध्यम से खोलते हैं जिसे हम उपयोग करते हैं या alt +2 दबाकर, अपना नाम लिखते हैं लोअरकेस और हिट अंत में प्रवेश करते हैं और फिर हमारे उपयोगकर्ता निर्देशिका के भीतर दो निर्देशिका (फ़ोल्डर) बनाते हैं, पहले के एक उपनिर्देशिका के रूप में एक Application_extras और दूसरे AntConc का नामकरण:

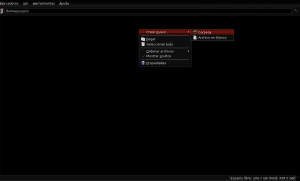
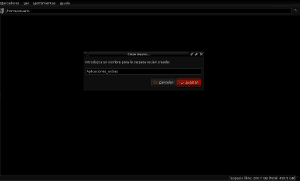
अब हम उस निर्देशिका में जाते हैं जहाँ antconc3.2.4u.tar.gz फ़ाइल डाउनलोड की गई थी (इस उदाहरण में डाउनलोड की जा रही है) और हम अपनी सामग्री को निकालने के लिए Xarchiver या फाइलरोलर के साथ फाइल को खोलते हैं, जो कि हमारे एंटेक ऑप्शन में से अर्कॉन ऑप्शन को चुनने के लिए है। फ़ाइल प्रबंधक और निर्देशिका पथ / घर / उपयोगकर्ता / विस्तृतीकरण / AntConc का संकेत:
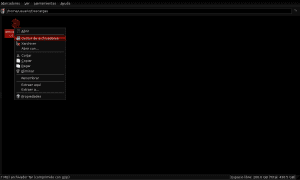
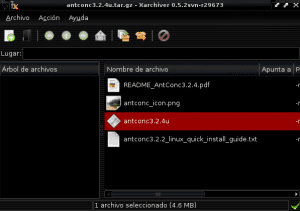
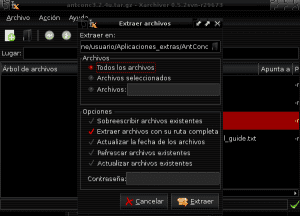
एक बार Antconc3.2.4u.tar.gz पैकेज की सामग्री को Application_extras के भीतर AntConc निर्देशिका में निकाल दिया गया है, हम सही माउस बटन के साथ क्लिक करके, निष्पादन प्रविष्टियाँ देने के लिए antconc3.2.4u फ़ाइल की पहचान करते हैं, गुण दर्ज करते हैं और अनुमति देते हैं कार्यक्रम के रूप में फ़ाइल का निष्पादन:
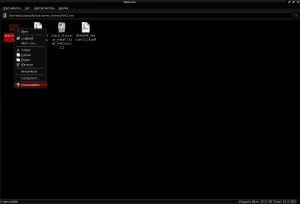
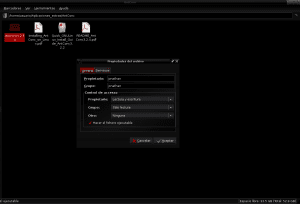
और इसके साथ ही हमें Antconc3.2.4u फ़ाइल पर माउस से डबल क्लिक करके AntConc को खोलने में सक्षम होना चाहिए।
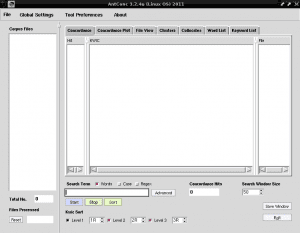
यदि हम पसंद करते हैं, तो हम टर्मिनल के माध्यम से पिछली सभी प्रक्रियाओं को निम्न आदेशों को निष्पादित करके और "उपयोगकर्ता" को उस नाम से बदलकर कर सकते हैं जिसे हम अपने सत्र में उपयोग करते हैं:
निर्देशिका बनाने के लिए:
$ mkdir / घर / उपयोगकर्ता / Applications_extras (प्रेस दर्ज करें)
$ mkdir / घर / उपयोगकर्ता / Applications_extras / AntConc (प्रेस दर्ज करें)
AntConc निर्देशिका में बदलें और antconc3.2.4u.tar.gz की सामग्री को निकालें:
$ cd / home / उपयोगकर्ता / Applications_extras / AntConc / (प्रेस दर्ज करें)
$ tar -xzvf /home/usuario/Descargas/antconc3.2.4u.tar.gz(press enter)
एक कार्यक्रम के रूप में antconc3.2.4u फ़ाइल को चलाने की अनुमति दें:
$ chmod + x antconc3.2.4u (हिट दर्ज करें)
और AntConc चलाएं:
$ /home/usuario/Aplicaciones_extras/AntConc/antconc3.2.4u(press enter)
हम जो भी प्रक्रिया चुनते हैं, चाहे जो भी हो, हम antconc3.2.4u फाइल को / usr / bin डायरेक्टरी में कॉपी कर सकते हैं और इसे टर्मिनल से AntConc चलाने में सक्षम होने के लिए आवश्यक अनुमति दे सकते हैं या alt + fc लेखन के साथ केवल antconc2 .3.2.4u। इसके लिए हम निम्नलिखित कमांड को सुपर या सूडो के रूप में निष्पादित करते हैं:
$ सू
(हम अपना रूट पासवर्ड लिखते हैं और एंटर करते हैं)
# cp / home/user/Extras_Applications/AntConc/antconc3.2.4u / usr / bin
# chmod a + rwx /usr/bin/antconc3.2.4u
# बाहर जाएं
और अब, बस किसी भी टर्मिनल एमुलेटर से हमारे उपयोगकर्ता के साथ antconc3.2.4u चलाकर, AntConc पिछली छवि में दिखाए गए अनुसार खुल जाएगा।
$antconc3.2.4u
किसी विशिष्ट वर्ण द्वारा शब्दों को सूचीबद्ध करने के लिए AntConc का उपयोग करना
AntConc को डाउनलोड करने और चलाने के तरीके की पहचान करने के बाद, अब हम लोअरकेस और अपरकेस दोनों में वर्णों के वर्णानुक्रम में खोज के माध्यम से कुछ शब्दों का पता लगाने के लिए इसके उपयोग को समझने का तरीका देंगे। यदि आप AntConc के संचालन और इसके उपयोग की सभी संभावनाओं के बारे में गहराई से जाना चाहते हैं, तो आप हमारी निर्देशिका / घर / उपयोगकर्ता / Aplicaciones.adras/ एंटीकॉन में दस्तावेज़ README_AntConc3.2.4.pdf से परामर्श कर सकते हैं या इसे http: //www.antlab से डाउनलोड कर सकते हैं .sci.waseda.ac.jp / software / antconc335 / AntConc_readme.pdf, साथ ही ऑनलाइन मदद लेने या AntConc वीडियो ट्यूटोरियल देखने के लिए इसकी वेबसाइट http://www.antlab.sci.waseda.ac। jp / पर उपलब्ध हैं। antconc_index.html
AntConc केवल सादे पाठ फ़ाइलों (".txt"), ".html", ".hml," ".xml" और इसके स्वयं के प्रारूप ".ant" के साथ काम कर सकता है, इसलिए दस्तावेज़ की सामग्री जिससे हम बनाएंगे। शब्द पहचान, हम इसे ".odt", ".rtf", ".pdf" या कुछ अन्य में "मूल।" से बदलकर सभी सामग्री का चयन करेंगे, इसे एक नए पाठ में कॉपी और पेस्ट करेंगे। डॉक्यूमेंट प्लेन हमारे पसंदीदा टेक्स्ट एडिटर (लीफपैड, गेडिट, विम, एमैक, अन्य के बीच)। इस उदाहरण में हम किताब से एक विषयगत सूचकांक बनाना चाहेंगे «ज्ञान का सहयोगात्मक निर्माण» जिससे हम इसकी वेबसाइट पर जा सकते हैं: http://seminario.edusol.info/seco3/ और जिसे हम स्वतंत्र रूप से इस लिंक से डाउनलोड कर सकते हैं। http: / /seminario.edusol.info/seco3/pdf/seco3.pdf

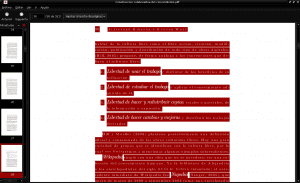
एक बार फ़ाइल डाउनलोड हो जाने के बाद, हम इसे अपनी डाउनलोड डायरेक्टरी में ढूंढते हैं, हम इसे अपने पीडीएफ डॉक्यूमेंट व्यूअर (इस उदाहरण एवियन में) से खोलते हैं, हम ctrl + a दबाकर इसकी सभी सामग्री का चयन करते हैं, हम इसे कॉपी करते हैं और इसे एक नए सादे में पेस्ट करते हैं पाठ दस्तावेज़:

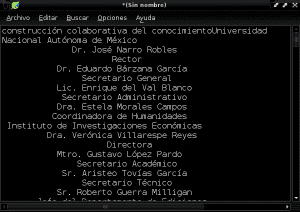
और हम अपने नए दस्तावेज़ को दस्तावेज़ निर्देशिका में «Construccion_colaborativa_del_conocimiento.txt» के नाम से सादे पाठ में सहेजते हैं:
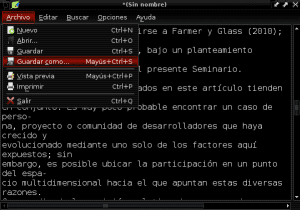
अब हम AntConc चलाते हैं और "फ़ाइल" नामक ऊपरी बाएँ पर पहले टैब से हम फ़ाइल "Construccion_colaborativa_del_knowledge.txt" खोलते हैं:
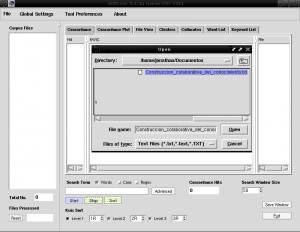
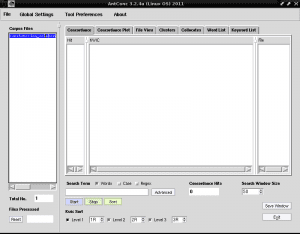
"Corpus Files" नामक बाएं कॉलम में अब हमारी टेक्स्ट फ़ाइल का नाम दिखाई देगा, जो दर्शाता है कि हम इस फाइल पर काम करेंगे, चूंकि AntConc में हम एक से अधिक टेक्स्ट फाइल लोड कर सकते हैं और उन पर या अलग से काम कर सकते हैं:
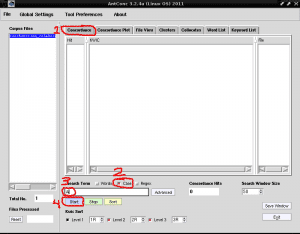
अब हम क्या करेंगे उन सभी शब्दों को सूचीबद्ध करेंगे जिनमें "ए" अक्षर शामिल हैं, इस कैपिटल लेटर के साथ एक कीवर्ड की पहचान करने के लिए, क्योंकि एंटकॉन हमें लोअरकेस और अपरकेस अक्षरों को अलग करने की संभावना प्रदान करता है, यह उचित नाम और समरूप की पहचान करने के लिए बहुत उपयोगी है एक सूची के रूप में। इसके लिए हम «Corpus Files» के दाईं ओर «Concordance» नामक पहला टैब लगाते हैं, हम «Case» बॉक्स को चिह्नित करने के लिए «Search» बॉक्स के नीचे दाईं ओर «Search Term» के निशान लगाते हैं, हम लिखते हैं फ़ील्ड में अक्षर A के नीचे खोजें और "स्टार्ट" कहने वाले बैंगनी आयत पर क्लिक करें:
और यह निम्नलिखित के परिणामों को सूचीबद्ध करेगा। आकार:
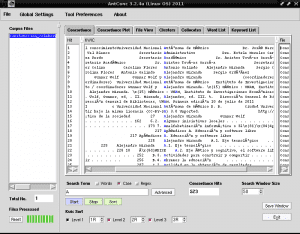
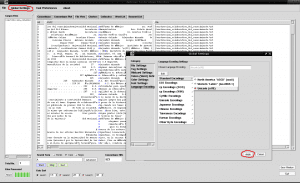
जैसा कि हम देख सकते हैं, लहजे के साथ लिखे गए कुछ अक्षर "ऑटोनोमा" के बजाय "ऑटोनोमा" शब्द के समान दिखाई देते हैं। ऐसा इसलिए है क्योंकि हमें AntConc को अपनी भाषा के लिए उपयुक्त एन्कोडिंग भाषा बतानी चाहिए, क्योंकि AntConc यह नहीं जानता है कि हम डिफ़ॉल्ट रूप से स्पेनिश का उपयोग कर रहे हैं। इसके लिए हम "फाइल" के बगल में सबसे ऊपर टैब "ग्लोबाल सेटिंग्स" को खोलते हैं, हम अंतिम विकल्प "भाषा एन्कोडिंग सेटिंग्स" पर जाते हैं दाईं ओर हम "एडिट" पर क्लिक करते हैं और पहला विकल्प "स्टैंडर्ड एन्कोडिंग्स" चुनते हैं। उस पर क्लिक करें, दाईं ओर "यूनिकोड (utf8)" प्रदर्शित होने वाली सूची से तीसरे विकल्प का चयन करें और हम खिड़की के निचले दाहिने हिस्से में "लागू करें" बॉक्स पर क्लिक करें:
परिवर्तनों को लागू करने के बाद, «स्टार्ट» के बैंगनी आयत पर फिर से क्लिक करें और उच्चारण वर्ण अब कानूनी रूप से दिखाई देंगे:
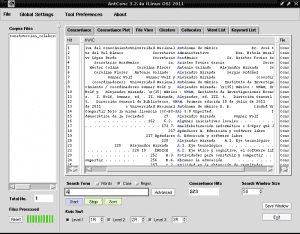
अब हम आसान पहचान के लिए नीले रंग में हाइलाइट किए गए अक्षर A के साथ शब्दों की समीक्षा कर रहे हैं और अपने विचारों के आधार पर, हम उन्हें चुन रहे हैं जिन्हें हम विषयगत सूचकांक में शामिल करना चाहते हैं, उदाहरण के लिए पंक्ति संख्या 17 में "कंप्यूटर निरक्षरता" सबसे आम है शब्द "ज्ञान के सहयोगात्मक निर्माण» "की सामग्री से हमारे विषयगत सूचकांक में संदर्भित होने वाला पहला शब्द पाया गया।
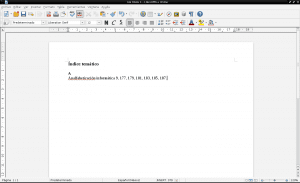
हम पीडीएफ दस्तावेज़ पर लौटते हैं «ज्ञान का सहयोगात्मक निर्माण» जिसमें खोजने के लिए पेज «कंप्यूटर निरक्षरता» टाइप करके प्रकट होता है «ctrl + f», खोज क्षेत्र में «निरक्षरता» शब्द लिखकर और अंत में «प्रवेश» दबाकर। सभी पृष्ठों पर खोजे गए शब्द का पता लगाना आवश्यक है। हम अपने विषय सूचकांक बनाने के लिए लिब्रे ऑफिस राइटर में एक नया दस्तावेज़ खोलते हैं या यदि हम मूल रूप से एक दस्तावेज़ की सामग्री पर काम कर रहे हैं, तो हम लिबर ऑफिस के साथ उस दस्तावेज़ को खोलते हैं और हम केवल किसी भी पृष्ठ पर इसके विषय सूचकांक को बनाएंगे और संपादित करेंगे। :

अगर हम AntConc के साथ भी पहचान करना चाहते हैं, जिसमें वाक्य "कंप्यूटर निरक्षरता" दस्तावेज़ की सभी सामग्री "Construccion_colaborativa_del_conocimiento.txt" में दिखाई देता है, तो हम खोज फ़ील्ड में "कंप्यूटर निरक्षरता" लिखते हैं, "केस", "शब्द" और "चिह्न" को अनचेक करें। इसे "प्रारंभ" पर क्लिक करें:
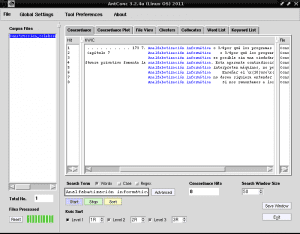
यदि हम «कंप्यूटर निरक्षरता» पर नीले रंग के साथ हाइलाइट किए गए किसी भी पंक्ति पर क्लिक करते हैं, उदाहरण के लिए पंक्ति 4 में, "फ़ाइल दृश्य» टैब में यह हमें पाठ का टुकड़ा दिखाएगा जहां यह चयन पृष्ठभूमि से काले रंग के साथ हाइलाइट किया गया है:
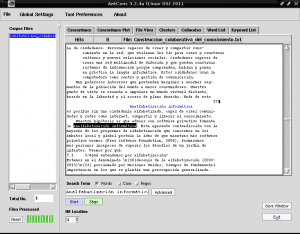
इस तरह, AntConc हमारे लिए बहुत उपयोगी है जब हमने एक पुस्तक, निबंध या सारांश लिखा है और हम समानांतर या विषयगत रूप से व्यवस्थित रूप से किसी कार्य के मुख्य विचारों का विश्लेषण नहीं कर रहे हैं ताकि इसकी रीडिंग को सुविधाजनक बनाया जा सके।
बहुत दिलचस्प उपकरण .. .. मैं इसके बारे में नहीं जानता था .. और यह मेरे लिए बहुत उपयोगी है ..
धन्यवाद ..
बहुत अच्छा लेख, दिलचस्प
साझा करने के लिए बहुत बहुत धन्यवाद
महान योगदान, बहुत उपयोगी है। यह जानते हुए कि आपके पास लिनक्स में इस प्रकार का टूल हो सकता है, हमेशा एक अंतर बनाता है। अभिवादन।
उत्कृष्ट प्रविष्टि। मुझे पसंद है कि वे इस प्रकार की सामग्री प्रकाशित करें!
नमस्ते। आपकी टिप्पणियों के लिए धन्यवाद और अब तक टिप्पणी करने में सक्षम होने के लिए माफी माँगता हूँ। मुझे आशा है कि जिन लोगों ने ट्यूटरिंग को व्यवहार में लाया है, उन्हें कोई समस्या नहीं हुई है।