Como eu estava ansioso para continuar a discutir este tópico, deixe-me contar um pouco da história, teoria e prática sobre vulnerabilidades. Todos nós já ouvimos que as falhas de segurança podem custar muito caro, todos sabemos que precisamos manter nosso software atualizado, todos sabemos que muitas atualizações são causadas por bugs de segurança. Mas hoje vou falar um pouco sobre como esses erros são encontrados e explorados 🙂 Mas antes vamos esclarecer alguns detalhes para ter uma melhor visão geral.
Antes de começar
Em primeiro lugar, quero dizer que vamos nos concentrar na primeira vulnerabilidade que aprendi a explorar, a conhecida Estouros de buffer, nesta vulnerabilidade aproveitamos a falta de verificação de memória para fazer coisas divertidas 🙂 Mas vamos esclarecer um pouco mais sobre isso.
Este não será um cenário do mundo real
Não posso me dar ao luxo de ensiná-los a quebrar qualquer programa que eles vejam - primeiro porque é perigoso para seus computadores, segundo porque isso exigiria mais do que minha cota normal de palavras.
Vamos em uma viagem aos anos 80
O que vou mostrar a vocês que posso fazer no meu laptop, mas não significa que pode ser feito hoje de uma forma simples 🙂 muitos desses conceitos já foram explorados tantas vezes que novos métodos de proteção e novos métodos para evadir eles surgiram 😛 mas isso nos leva de volta ao mesmo lugar, não há espaço para poder contar tudo isso 🙂
Pode não funcionar no seu processador
Embora eu vá usar um exemplo muito simples, quero que fique bem claro desde o início que os detalhes disso são tantos e tão variados que, assim como pode sair igual a mim, se você quiser experimentar , o efeito desejado também pode não ser alcançado 🙂 Mas vocês podem imaginar que não posso explicar isso neste espaço, até porque com esta introdução já peguei mais de 300 palavras, então vamos direto ao nosso ponto.
Que e um Estouro de buffer
Para responder a isso, primeiro temos que entender a primeira metade dessa combinação.
Buffers
Uma vez que tudo se trata de memória em um computador, é lógico que deve haver algum tipo de recipiente de informações. Quando falamos sobre inputs o outputs, chegamos diretamente ao conceito de buffers. Para ser breve, um amortecer É um espaço de memória de tamanho definido no qual vamos armazenar uma quantidade de informações, simples 🙂
Overflows ocorrem, como o nome indica, quando um buffer é preenchido com mais informações do que pode conter. Mas por que isso é importante?
Pilha
Também conhecidas como pilhas, são um tipo de dados abstratos em que podemos pilha informações, sua principal característica é que eles têm um UEPS (último a entrar, primeiro a sair). Vamos pensar por um segundo em uma pilha de pratos, nós os colocamos em cima um por um, e então os retiramos um a um de cima, isso faz com que o último prato que colocamos (aquele que está no topo ) é o primeiro prato que vamos retirar, obviamente se só pudermos retirar um prato de cada vez e decidirmos fazê-lo nesta ordem: P.
Agora que você conhece esses dois conceitos, temos que colocá-los em ordem. As pilhas são importantes porque cada programa que executamos tem seu próprio pilha de execução. Mas esta pilha tem um recurso específico, cresce para baixo. A única coisa que você precisa saber sobre isso é que, enquanto um programa está em execução, quando uma função é chamada, a pilha vai de um número X na memória para um número (Xn). Mas para continuar, devemos entender mais um conceito.
Ponteiros
Este é um conceito que enlouquece muitos programadores quando iniciam no mundo C, na verdade o grande poder da programação C se deve em parte ao uso de ponteiros. Para simplificar, um ponteiro aponta para um endereço de memória. Isso parece complexo, mas não é tão complexo, todos nós temos RAM em nossas máquinas, certo? Bem, isso pode ser definido como um arranjo consecutivo de blocos, essas localizações são normalmente expressas em números hexadecimais (de 0 a 9 e, em seguida, de A a F, como 0x0, 0x1, 0x6, 0xA, 0xF, 0x10). Aqui, como uma nota curiosa, 0x10 NÃO é igual a 10 😛 se convertermos para a ordem decimal seria o mesmo que dizer 15. Isso é algo que também confunde mais de um no início, mas vamos direto ao assunto.
Registros
Os processadores trabalham com vários registros, que funcionam para transmitir localizações da memória física para o processador, para arquiteturas que usam 64 bits, o número de registros é grande e difícil de descrever aqui, mas para se ter uma ideia, os registros são como ponteiros, indicam entre outras coisas , um espaço de memória (localização).
Agora pratique
Eu sei que tem sido muita informação para processar até agora, mas na realidade são questões um tanto complexas que tento explicar de uma forma muito simples, veremos um pequeno programa que usa buffers e vamos quebrar para entender isso sobre overflows, obviamente este não é. É um programa real, e vamos "fugir" de muitas das contramedidas que são usadas hoje, apenas para mostrar como as coisas eram feitas antes 🙂 e por causa de algumas dessas princípios são necessários para aprender coisas mais complexas 😉
GDB
Um grande programa que é sem dúvida um dos mais utilizados pelos programadores C. Entre as suas muitas virtudes temos o facto de nos permitir ver tudo isto de que falámos até agora, os registos, a pilha, os buffers, etc. Vamos ver o programa que usaremos em nosso exemplo.
retinput.c

Próprio. Christopher Diaz Riveros
Este é um programa bastante simples, vamos usar a biblioteca stdio.h para poder obter informações e exibi-las em um terminal. Podemos ver uma função chamada return_input que gera um amortecer chamado ordem, que tem um comprimento de 30 bytes (o tipo de dados char tem 1 byte).
A função gets(array); solicitar informações por console e função printf() retorna o conteúdo do array e o exibe na tela.
Todo programa escrito em C começa com a função main(), este só se encarregará de chamar return_input, agora vamos compilar o programa.

Próprio. Christopher Diaz Riveros
Vamos ver um pouco do que acabei de fazer. Opção -ggdb diz ao gcc para compilar o programa com informações para que o gdb possa depurar adequadamente. -fno-stack-protector É uma opção que obviamente não deveríamos usar, mas que usaremos porque caso contrário seria possível gerar o estouro de buffer na pilha. No final, testei o resultado. ./a.out ele apenas executa o que acabei de compilar, me pede informações e as retorna. Correndo 🙂
Advertências
Outra nota aqui. Você pode ver os avisos? claramente é algo a levar em conta quando trabalhamos com código ou compilamos, isso é um pouco óbvio e existem poucos programas que hoje têm a função gets() No código. Uma vantagem do Gentoo é que compilando cada programa, eu posso ver o que pode estar errado, um programa "ideal" não deveria tê-los, mas você ficaria surpreso com quantos programas grandes têm esses avisos porque eles são MUITO grandes e é difícil controlá-los. funções perigosas quando há muitos avisos ao mesmo tempo. Agora se continuarmos
Depurando o programa
Próprio. Christopher Diaz Riveros
Agora, esta parte pode ser um pouco confusa, mas como já escrevi um pouco, não posso me dar ao luxo de explicar tudo, desculpe se você vê que estou indo rápido demais 🙂
Desarmando o código
Vamos começar examinando nosso programa de linguagem de máquina compilado.

Próprio. Christopher Diaz Riveros
Este é o código de nossa função principal em Montagem, isso é o que nosso processador entende, a linha à esquerda é o endereço físico na memória, o <+ n> é conhecido como compensar, basicamente a distância entre o início da função (principal) e essa instrução (conhecida como opcode) Então vemos o tipo de instrução (push / mov / callq ...) e um ou mais registradores. Resumido podemos dizer que é a indicação seguida da origem / origem e destino. <return_input> refere-se à nossa segunda função, vamos dar uma olhada.
return_input
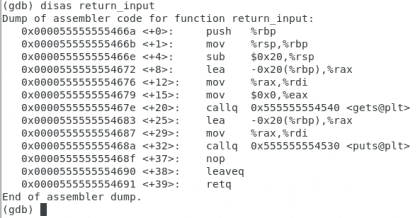
Próprio. Christopher Diaz Riveros
Isso é um pouco mais complexo, mas eu só quero que você verifique algumas coisas, há uma tag chamada <gets@plt> e um último opcode chamado retq indicando o fim da função. Vamos colocar alguns pontos de interrupção, um na função gets e outro no retq.

Próprio. Christopher Diaz Riveros
Execute
Agora vamos executar o programa para ver como a ação começa.
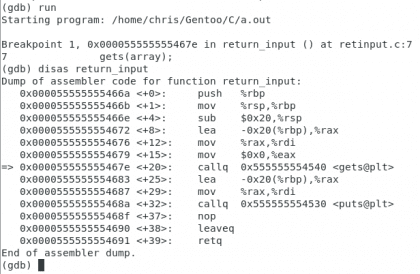
Próprio. Christopher Diaz Riveros
Podemos ver que uma pequena seta aparece indicando o opcode onde estamos, quero que eles levem em consideração a direção 0x000055555555469b, este é o endereço após a ligação para return_input em função main , isso é importante porque é para onde o programa deve retornar quando você terminar de receber o entrada, vamos entrar na função. Agora vamos verificar a memória antes de entrar na função gets.

Próprio. Christopher Diaz Riveros
Coloquei a função principal de volta para você e destaquei o código ao qual me referia, como você pode ver, devido ao endianness foi separado em dois segmentos, quero que eles levem em consideração a direção 0x7fffffffdbf0 (o primeiro da esquerda após o comando x/20x $rsp) uma vez que este é o local que devemos usar para verificar os resultados de get, vamos continuar:
Quebrando o programa
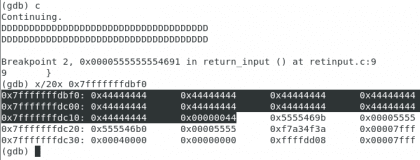
Próprio. Christopher Diaz Riveros
Eu destaquei aqueles 0x44444444porque eles são a representação de nossos Ds 🙂 agora começamos a adicionar entrada ao programa, e como você pode ver, estamos a apenas duas linhas do endereço desejado, vamos preenchê-lo até estarmos um pouco antes dos endereços que destacamos na etapa anterior.
Mudando o caminho de retorno
Agora que conseguimos entrar nesta seção do código onde indica o retorno da função, vamos ver o que acontece se mudarmos o endereço 🙂 em vez de ir para a localização do opcode que segue aquele que tínhamos um momento atrás, o que você acha se voltarmos para return_input? Mas para isso é necessário escrever o endereço que queremos em binário, faremos isso com a função printf do bash 🙂
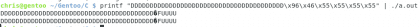
Próprio. Christopher Diaz Riveros
Agora recebemos a informação duas vezes - certamente o programa não foi feito para isso, mas conseguimos quebrar o código e fazê-lo repetir algo que não era para fazer.
reflexões
Esta simples mudança pode ser considerada um explorar muito básico 🙂 ele conseguiu quebrar o programa e fazer algo que queremos que ele faça.
Este é apenas o primeiro passo em uma lista quase infinita de coisas para ver e adicionar, existem maneiras de adicionar mais coisas do que simplesmente repetir um pedido, mas desta vez eu escrevi muito e tudo relacionado a codificação de shell é um assunto para escrever mais do que artigos, livros completos, eu diria. Desculpe se não consegui aprofundar um pouco mais nos tópicos que gostaria, mas com certeza terei uma chance 🙂 Saudações e obrigado por estar aqui.
Seja mais direto. Escreva menos e concentre-se no que é importante
Oi, obrigado pelo comentário.
Pra falar a verdade cortei boa parte das ideias, mas mesmo assim me pareceu que deixou o mínimo para que quem não tem conhecimento de programação possa ter uma ideia.
lembranças
O problema é que quem não tem conhecimento de programação não vai descobrir nada porque é muito complexo para começar, mas quem sabe programar gosta de ser mais direto.
Suponho que você não pode atingir a todos, você tem que escolher, e neste caso você pecou para querer cobrir muito.
Aliás, te digo como uma crítica construtiva, adoro esses temas e gostaria que continuassem escrevendo artigos, parabéns!
Eu acho o mesmo.
Muito obrigado a ambos !! Certamente é difícil entender como atingir o público-alvo quando a verdade é que o número de pessoas com nível avançado de programação que lêem esses artigos é baixo (pelo menos isso pode ser inferido com base nos comentários)
Certamente pequei por querer simplificar algo que requer uma ampla base de conhecimento para ser compreendido. Espero que você entenda que, como estou apenas começando no blog, ainda não descobri o ponto exato em que meus leitores sabem e entendem o que estou dizendo. Isso tornaria muito mais fácil dizer a verdade 🙂
Tentarei ser mais curto quando merecer sem despersonalizar o formato, já que separar a forma de escrever do conteúdo é um pouco mais complicado do que se possa imaginar, pelo menos os tenho bastante vinculados, mas suponho que em última instância poderei para adicionar linhas em vez de cortar o conteúdo.
lembranças
Onde você poderia saber mais sobre o assunto? Algum livro recomendado?
O exemplo foi tirado do Manual do Shellcoder de Chris Anley, John Heasman, Felix Linder e Gerardo Richarte, mas, para fazer a tradução de 64 bits, tive que aprender sobre minha arquitetura, o manual do desenvolvedor intel, os volumes 2 e 3 são um fonte bastante confiável para isso. Também é bom ler a documentação do GDB, que vem com o comando 'info gdb', Para aprender Assembly e C existem muitos livros muito bons, exceto que os livros de Assembly são um pouco antigos, então há uma lacuna a ser preenchida com outro tipo documentação.
O shellcode em si não é mais tão eficaz atualmente por vários motivos, mas ainda é interessante aprender novas técnicas.
Espero que ajude um pouco 🙂 Saudações
Bom artigo, blog antigo desdelinux renasceu novamente =)
Quando você diz que o shell remoto não é tão eficaz, está se referindo a contramedidas projetadas para mitigar ataques, eles chamam de segurança ofensiva.
Saudações e continue assim
Muito obrigado, Franz words palavras muito gentis, na verdade eu quis dizer que o Shellcoding hoje é muito mais complexo do que vemos aqui. Temos o ASLR (gerador de localização de memória aleatória), o protetor de pilha, as várias medidas e contra-medidas que limitam o número de opcodes que podem ser injetados em um programa, e isso é apenas o começo.
Atenciosamente,
Olá, você fará outra parte ampliando o tópico? É interessante
Olá, o tema é certamente bastante interessante, mas o nível de complexidade que assumiríamos ficaria muito alto, provavelmente envolvendo um grande número de postagens para explicar os diversos pré-requisitos para entender o outro. Provavelmente escreverei sobre isso, mas não serão os próximos posts, quero escrever alguns tópicos antes de continuar com este.
Saudações e obrigado por compartilhar
Muito bom che! Você está contribuindo com ótimas postagens! Uma pergunta: estou começando essa coisa de segurança de TI lendo um livro chamado "Assuring security by pen test". Este livro é recomendado? Como você sugere que eu comece a perguntar sobre essas questões?
Olá cacto, é todo um universo de vulnerabilidades e outros, para falar a verdade depende muito do que te chama a atenção, e das necessidades que tens, um gerente de TI não precisa saber o mesmo que um pen-tester, Ou um pesquisador de vulnerabilidade ou um analista forense, uma equipe de recuperação de desastres tem um conjunto muito diferente de habilidades. Obviamente cada um deles requer um nível diferente de conhecimento técnico, recomendo que você comece a descobrir exatamente o que você gosta, e comece a devorar livros, artigos e outros, e o mais importante, pratique tudo que você lê, mesmo que esteja desatualizado , isso vai fazer a diferença no final.
Atenciosamente,
Olá.
Muito obrigado por explicar este tópico, bem como por comentar que para informações extras temos o "Manual do Shellcoder". Já tenho uma leitura pendente 😉