Buenas con todos 🙂 Antes de continuar con los textos de la lista de pedidos, quiero celebrar el lanzamiento de git 2.16 agradeciendo a cada uno de los que mandó un parche y a cada uno de los usuarios, en total tuvimos como 4000 líneas entre actualizaciones y correcciones, lo cual no habla muy bien de mi primera versión, pero si de la amabilidad de ustedes 🙂 ¡Gracias! Ahora bien, les contaré un pequeño secreto, hasta ahora no ha habido una vez en la que no me haya sentado a escribir un artículo y haya pensado mucho al respecto, normalmente solo escribo de corrido, y después el buen lagarto se toma la amabilidad de corregir mis faltas de tipeo 🙂 así que gracias a él también.
Esto no es lo mejor cuando hablamos de escribir artículos, supuestamente debería tener un objetivo y armar una estructura, y marcar pequeños puntos y revisiones y etc etc… Ahora bien, esto no solo aplica para los blogs en general, sino que es fundamental en un software que pretende ser bueno 🙂 Para esta tarea, y tras algunos problemas con el software de control de versiones que se usaba en el desarrollo del kernel hace unos años, nació git 🙂
¿Dónde aprender git?
La cantidad de documentación existente en torno a git es descomunal, incluso si solo tomamos las páginas de manual que vienen con la instalación, tendríamos una cantidad inmensa de lectura. Yo personalmente encuentro el libro de git bastante bien diseñado, incluso yo he traducido algunos de los segmentos de la sección 7, todavía me faltan unos cuantos, pero denme tiempo 😛 tal vez en este mes pueda traducir lo que queda de esa sección.
¿Qué hace git?
Git está diseñado para ser rápido, eficiente, simple y soportar grandes cargas de información, después de todo, la comunidad del kernel lo creo para su software, el cual es uno de los trabajos conjuntos más grandes del software libre del mundo y cuenta con cientos de contribuciones por hora en una base de código que supera el millón de líneas.
Lo interesante de git es su forma de mantener las versiones de la data. Antiguamente (otros programas de control de versiones) tomaban comprimidos de todos los archivos existentes en un punto de la historia, como hacer un backup. Git tiene un enfoque diferente, al realizar un commit se marca un punto en la historia, ese punto en la historia cuenta con una serie de modificaciones y trabajos, al final del día, se juntan todas las modificaciones a lo largo del tiempo y se obtienen los archivos para poder comprimir o marcar como hitos de versiones. Como sé que todo esto suena complicado, voy a llevarlos por un mágico viaje en un ejemplo super básico.
Pequeño proyecto de calculamática
La calculamática será un programa que encontrará los cuadrados de un número dado, lo haremos en C y será lo más simple posible, así que no esperen muchos controles de seguridad de mi parte. Primero vamos a crear un repositorio, lo haré con Github para matar dos pájaros de un tiro:

Diseño propio. Christopher Díaz Riveros
Hemos agregado un par de cosas bastante simples como la licencia (muy importante si quieres proteger tu trabajo, en mi caso, obligarlos a compartir los resultados si lo quieren usar de base :P)
Ahora vamos a ir a nuestra querida terminal, git clone es el comando que se encarga de descargar el repositorio ubicado en la url asignada y crear una copia local en nuestro equipo.
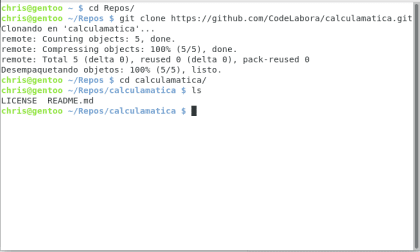
Diseño propio. Christopher Díaz Riveros
Ahora vamos a revisar con git log lo que ha ocurrido en la historia de nuestro proyecto:
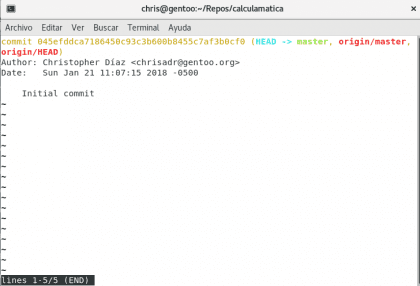
Aquí tenemos mucha información en diversos colores 🙂 vamos a tratar de explicarla:
la primer línea amarilla es el «código de barras del commit» cada commit tiene su propio identificador único, con el cual puedes hacer bastantes cosas, pero lo vamos a dejar para después. Ahora tenemos HEAD de celeste y master de verde. Estos son «punteros» su función es apuntar a la ubicación actual de nuestra historia (HEAD) y la rama en la que estamos trabajando en nuestra computadora (master).
origin/master es la contraparte de internet, origin es el nombre por defecto que se ha asignado a nuestra URL, y master es la rama en la que está trabajando… para hacerlo sencillo, los que tienen un / son aquellos que no se encuentran en nuestro equipo, sino que son referencias a lo que está en internet.
Después tenemos el autor, la fecha y hora y el resumen del commit. Esta es una pequeña reseña de lo que ha sucedido en ese punto de la historia, muy importante en muchos proyectos y ahí se condenza bastante informaicón. Vamos a ver más de cerca lo que sucedió en el commit con el comando git show <código-de-commit>
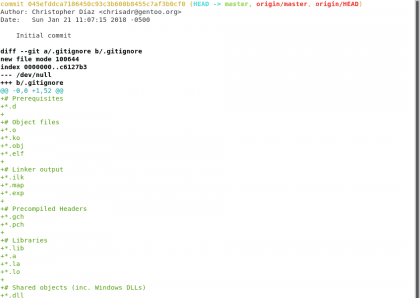
Diseño propio. Christopher Díaz Riveros
El comando git show nos lleva a esta pantalla en formato parche, donde se aprecia lo que se ha agregado y lo que se ha quitado (si se hubiese quitado algo) en ese momento de la historia, hasta aquí solo nos muestra que se agregaron los archivos .gitignore,README.md y LICENSE.
Ahora vamos a lo nuestro, vamos a escribir un archivo 🙂 crearemos el primer hito en nuestra historia 😀 :
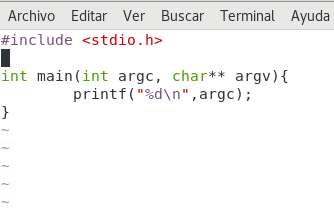
Diseño propio. Christopher Díaz Riveros
Brevemente, vamos a crear un programa que nos muestre la cantidad de argumentos pasados al momento de ejecutarlo, simple 🙂
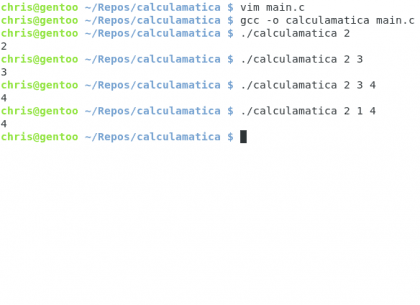
Diseño propio. Christopher Díaz Riveros
Eso fue fácil 🙂 ahora vamos a ver el siguiente comando útil: git status
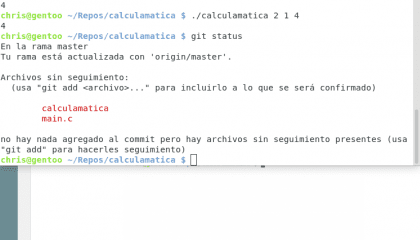
Diseño propio. Christopher Díaz Riveros
Algún alma de buen corazón ha traducido git para hacerlo sencillo de seguir, aquí tenemos mucha información útil, sabemos que estamos en la rama master, que estamos actualizados con origin/master(la rama de Github), ¡que tenemos archivos sin seguimiento! y que para agregarlos tenemos que usar git add, vamos a probar 🙂
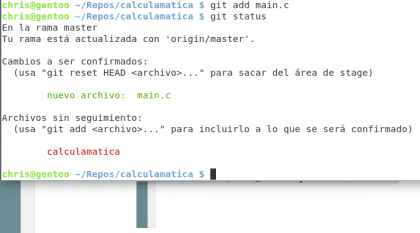
Diseño propio. Christopher Díaz Riveros
Ahora tenemos un nuevo espacio de verde, en el cual se muestra el archivo que hemos agregado a la zona de trabajo. En este lugar podemos agrupar nuestros cambios para poder realizar un commit, el commit consiste en un hito a lo largo de la historia de nuestro proyecto, vamos a crear el commit 🙂 git commit
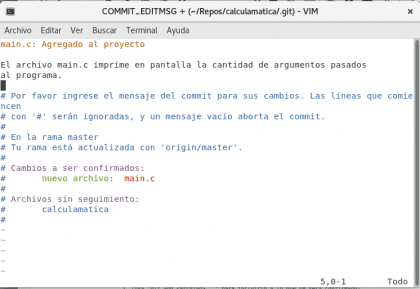
Diseño propio. Christopher Díaz Riveros
Brevemente explicado, la línea amarilla es el título de nuestro commit, yo escribo main.c por una mera referencia visual. El texto de negro es la explicación de los cambios realizados desde el commit anterior hasta ahora 🙂 guardamos el archivo y veremos nuestro commit guardado en el registro.
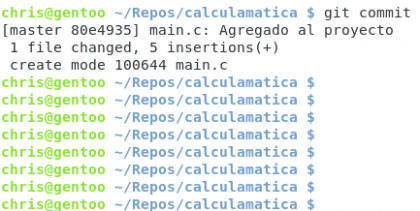
Diseño propio. Christopher Díaz Riveros
Ahora vamos a ver la historia de nuestro proyecto con git log
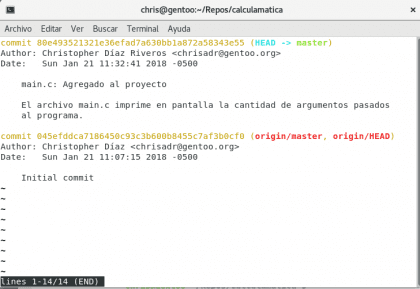
Diseño propio. Christopher Díaz Riveros
Nuevamente en el log, ahora podemos ver que la línea verde y la roja han diferido, eso se debe a que en nuestra computadora, estamos un commit por encima de los almacenados en internet 🙂 vamos a seguir el trabajo, supongamos que ahora quiero mostrar un mensaje en caso de que el usuario ponga más de un argumento en el programa (lo cual haría que la calculadora se confunda 🙂 )
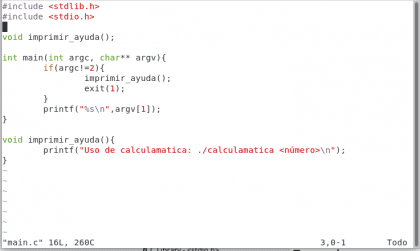
Como podemos ver, nuestro programa ha crecido bastante 😀 , ahora tenemos la función imprimir_ayuda() que muestra un mensaje sobre cómo usar la calculamatica, y en el bloque main() ahora hacemos una revisión con if(algo que veremos en un tutorial de programación en otro momento, por ahora solo es necesario saber que si se ingresan más de 2 argumentos a la calculamática, que el programa termine y se muestre la ayuda. Vamos a ejecutarlo:

Diseño propio. Christopher Díaz Riveros
Como pueden ver ahora imprime el número que ha sido entregado en lugar de la cantidad de argumentos, pero eso yo no se los había contado antes 🙂 para los curiosos echo $? muestra el código de salida del último programa ejecutado, el cual es 1 porque ha terminado en error. Ahora vamos a revisar cómo va nuestra historia:
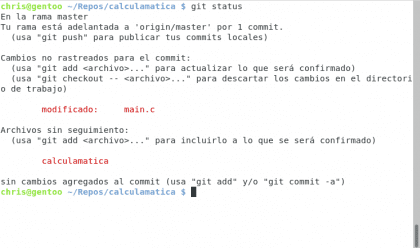
Diseño propio. Christopher Díaz Riveros
Ahora sabemos que estamos 1 commit delante de Github, que el archivo main.c ha sido modificado, vamos a crear el siguiente commit haciendo git add main.c y luego git commit🙂

Diseño propio. Christopher Díaz Riveros
Ahora hemos sido un poco más específicos, puesto que hemos implementado una función y cambiado el código de validación. Ahora que se ha guardado vamos a revisar nuestro último cambio. Podemos verlo con git show HEAD
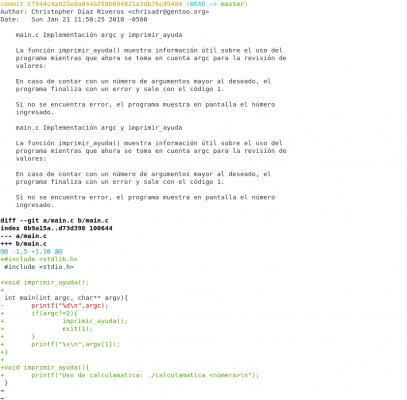
Diseño propio. Christopher Díaz Riveros
Ahora se pueden apreciar las líneas rojas y verdes, hemos agregado la biblioteca stdlib.h, modificado gran parte del código y agregado la función a nuestra historia.
Ahora vamos a ver el log: (git log)

Diseño propio. Christopher Díaz Riveros
Podemos ver que estamos dos commits adelante de la versión de Github, vamos a igualar un poco el marcador 🙂 para eso usamos git push origin master
Con esto decimos, envía mis commits al url origin en la rama master
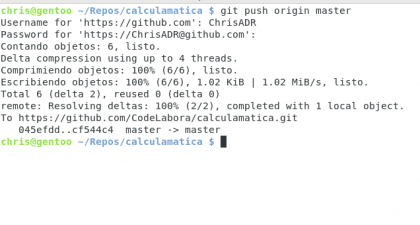
Diseño propio. Christopher Díaz Riveros
¡Felicidades! Ahora sus cambios están en Github, ¿no me creen? vamos a revisarlo 😉
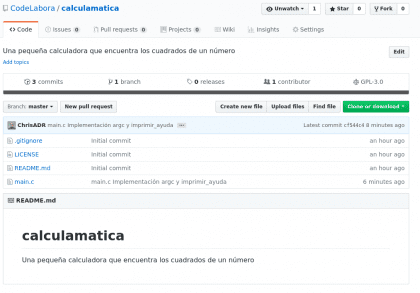
Diseño propio. Christopher Díaz Riveros
Ahora tenemos los 3 commits en Github 🙂
Resumen
Hemos tocado los aspectos más básicos de git, ahora pueden crear un flujo de trabajo simple en sus proyectos, esto no es casi nada de toda la gran variedad de cosas que pueden hacerse con git, pero ciertamente es lo más práctico y de todos los días para un desarrollador o blogger. No hemos llegado al final de la calculadora, pero eso lo vamos a dejar para otro momento 😉 Muchas gracias por llegar hasta aquí y espero les ayude a participar en varios proyectos 😀 Saludos
Buenas… no sé si a ustedes, pero yo no puedo ver las imágenes de éste informe…
Saludos
Era un problema con mí navegador. Diculpen la molestia.
Aún tengo que leerlo a más detalles, soy novato.
Buenísimo artículo para empezar con git, aunque recomiendo ir tomando apuntes para comprender el detalle.
No me ha quedado claro un par de cosas:
para qué sirve la opción Add .gitignore C, aunque supongo que lo veré cuando lo practique,
por qué hay que volver a hacer git add main.c antes del siguiente git commit, ¿el add main.c avisa a git que compare ese fichero con la versión en red? ¿no compara automáticamente todos los ficheros añadidos para seguimiento?
Hola Guillermo 🙂 que bueno que lo hayas encontrado útil, para responder tus dudas:
.gitignore es un archivo que le indica a git qué formatos o patrones ignorar, en este caso seleccionar C hace que se igneron archivos .o y otros que se generan al momento de compilación, lo que es bueno porque sino tu git se volvería loco al momento de cada compilación y seguimiento 🙂 puedes revisar la gran cantidad de formatos que git omite en su template de C haciendo cat o con algún editor de texto.
Si bien git va a llevar un seguimiento de cada archivo agregado al árbol de trabajo, es necesario seleccionar específicamente qué archivos van a entrar en el commit siguiente, para ponerte un ejemplo, supongamos que tu trabajo te ha llevado a modificar 5 archivos distintos antes de poder ver el resultado. Si tu quieres ser un poco más específico y explicar qué se hace en cada uno, puedes hacer git add archivo1; git commit;git add archivo2;git commit….3,4,5; git commit. De esta manera tu historia queda limpia y los cambios bien definidos. Y en caso de tener que cambiar alguna cosa, o revertir (temas más avanzados) podrías revertir cosas específicas o agregar cosas específicas sin cambiar el resto.
Espero que ayude 🙂 saludos y gracias por preguntar
PS: git add no dice que compare con la versión en la red, sino con el commit anterior en tu línea de trabajo, si ha sido local (verde) lo va a comparar con ese, si ha sido remoto (rojo) lo va a comparar con ese otro. Solo para aclarar 😉
Perfecto, claro que aclara.