Dato che non vedevo l'ora di continuare a discutere di questo argomento, lascia che ti racconti un po 'di storia, teoria e pratica sulle vulnerabilità. Ormai abbiamo tutti sentito che le falle di sicurezza possono costare molto, sappiamo tutti che dobbiamo mantenere aggiornato il nostro software, sappiamo tutti che molti aggiornamenti sono causati da errori di sicurezza. Ma oggi vi parlerò un po 'di come questi errori vengono trovati e sfruttati 🙂 Ma prima di questo chiariremo alcuni dettagli per avere una migliore visione d'insieme.
Prima di cominciare
Per prima cosa voglio dirti che ci concentreremo sulla prima vulnerabilità che ho imparato a sfruttare, quella conosciuta Buffer overflow, in questa vulnerabilità approfittiamo della mancanza di verifica della memoria per fare cose divertenti 🙂 Ma chiariamo un po 'di più al riguardo.
Questo non sarà uno scenario del mondo reale
Non posso permettermi di insegnare loro a rompere qualsiasi programma che guardano, primo perché è pericoloso per i loro computer, secondo perché ci vorrebbe più della mia solita quota di parole.
Facciamo un viaggio negli anni '80
Quello che ti mostrerò che posso fare sul mio laptop, ma non significa che possa essere fatto oggi in modo semplice 🙂 molti di questi concetti sono già stati sfruttati così tante volte che nuovi metodi di protezione e nuovi metodi per eludere sono emersi 😛 ma questo ci riporta allo stesso posto, non c'è spazio per poter raccontare tutto ciò 🙂
Potrebbe non funzionare sul tuo processore
Anche se userò un esempio molto semplice, voglio che sia abbastanza chiaro fin dall'inizio che i dettagli di questo sono così tanti e così vari che così come può venire fuori come me, se vuoi provarlo , l'effetto desiderato potrebbe anche non essere ottenuto 🙂 Ma potete immaginare che non posso spiegarlo in questo spazio, soprattutto perché con questa introduzione ho già preso più di 300 parole, quindi arriviamo subito al nostro punto.
Cos'è un file Buffer Overflow
Per rispondere a questa domanda dobbiamo prima capire la prima metà di questa combinazione.
buffer
Poiché tutto riguarda la memoria in un computer, è logico che ci debba essere un qualche tipo di contenitore di informazioni. Quando parliamo di Ingressi o uscite, arriviamo direttamente al concetto di tamponi. Per farla breve, a bufferizzare È uno spazio di memoria di dimensioni definite in cui memorizzeremo una quantità di informazioni, semplice 🙂
Gli overflow si verificano, come suggerisce il nome, quando un buffer si riempie di più informazioni di quante ne possa gestire. Ma perché è così importante?
pila
Conosciuti anche come stack, sono un tipo di dati astratto in cui possiamo pila informazioni, la loro caratteristica principale è che hanno un ordinamento LIFO (ultimo arrivato primo uscito). Pensiamo per un secondo a una pila di piatti, li mettiamo sopra uno per uno e poi li tiriamo fuori uno ad uno dall'alto, questo fa l'ultimo piatto che abbiamo messo (quello che sta in alto ) è il primo piatto che andiamo a togliere, ovviamente se ne possiamo estrarre solo un piatto alla volta e decidiamo di farlo in quest'ordine: P.
Ora che conosci questi due concetti, dobbiamo metterli in ordine. Gli stack sono importanti perché ogni programma che eseguiamo ha i suoi stack di esecuzione. Ma questo stack ha un'estensione caratteristica particolare, cresce. L'unica cosa che devi sapere su questo è che mentre un programma è in esecuzione, quando viene chiamata una funzione, lo stack passa da un numero X in memoria a un numero (Xn). Ma per continuare dobbiamo capire un altro concetto.
Puntatori
Questo è un concetto che fa impazzire molti programmatori quando iniziano nel mondo del C, infatti il grande potere della programmazione in C è dovuto in parte all'uso dei puntatori. Per mantenerlo semplice, un puntatore punta a un indirizzo di memoria. Sembra complesso, ma non è così complesso, abbiamo tutti la RAM nelle nostre macchine, giusto? Bene, questo può essere definito come un file disposizione consecutiva di blocchi, queste posizioni sono normalmente espresse in numeri esadecimali (da 0 a 9 e quindi da A a F, come 0x0, 0x1, 0x6, 0xA, 0xF, 0x10). Qui come nota curiosa, 0x10 NO è uguale a 10 😛 se lo convertiamo in decimale sarebbe come dire 15. Questo è qualcosa che all'inizio confonde anche più di uno, ma passiamo al punto.
Records
I processori funzionano con una serie di record, che funzionano per trasmettere posizioni dalla memoria fisica al processore, per architetture che utilizzano 64 bit, il numero di registri è grande e difficile da descrivere qui, ma per avere un'idea, i registri sono come puntatori, indicano tra le altre cose , uno spazio di memoria (posizione).
Adesso esercitati
So che sono state molte le informazioni da elaborare fino ad ora, ma in realtà sono questioni alquanto complesse che cerco di spiegare in un modo molto semplice, vedremo un piccolo programma che usa i buffer e andremo a romperlo per capire questo sugli overflow, ovviamente questo non lo è È un programma reale e "eluderemo" molte delle contromisure che vengono utilizzate oggi, solo per mostrare come si facevano le cose prima 🙂 e perché alcune sono necessari principi per poter imparare cose più complesse 😉
GDB
Un ottimo programma che è senza dubbio uno dei più utilizzati dai programmatori C. Tra le sue tante virtù abbiamo il fatto che ci permette di vedere tutto ciò di cui abbiamo parlato finora, i registri, lo stack, i buffer, ecc. 🙂 Vediamo il programma che useremo per il nostro esempio.
reinput.c

Proprio. Christopher Diaz Riveros
Questo è un programma abbastanza semplice, useremo la libreria stdio.h per poter ottenere informazioni e visualizzarle in un terminale. Possiamo vedere una funzione chiamata return_input che genera un file bufferizzare detto schieramento, che ha una lunghezza di 30 bytes (il tipo di dati char è lungo 1 byte).
La funzione gets(array); richiedere informazioni per console e funzione printf() restituisce il contenuto dell'array e lo visualizza sullo schermo.
Ogni programma scritto in C inizia con la funzione main(), questo sarà solo incaricato di chiamare return_input, ora compileremo il programma.

Proprio. Christopher Diaz Riveros
Diamo un po 'di quello che ho appena fatto. L'opzione -ggdb dice a gcc di compilare il programma con le informazioni affinché gdb possa eseguire correttamente il debug. -fno-stack-protector È un'opzione che ovviamente non dovremmo usare, ma che useremo perché altrimenti sarebbe possibile generare il buffer overflow nello stack. Alla fine ho testato il risultato. ./a.out esegue solo quello che ho appena compilato, mi chiede informazioni e le restituisce. In esecuzione 🙂
Avvertenze
Un'altra nota qui. Riesci a vedere gli avvertimenti? chiaramente è qualcosa da tenere in considerazione quando lavoriamo con il codice o compiliamo, questo è un po 'ovvio e ci sono pochi programmi che oggi hanno la funzione gets() Nel codice. Un vantaggio di Gentoo è che compilando ogni programma, posso vedere cosa potrebbe esserci di sbagliato, un programma "ideale" non dovrebbe averli, ma saresti sorpreso di quanti programmi di grandi dimensioni hanno questi avvisi perché sono MOLTO grandi ed è è difficile tenerne traccia Funzioni pericolose quando ci sono molti avvisi contemporaneamente. Ora se continuiamo
Debug del programma
Proprio. Christopher Diaz Riveros
Ora questa parte può creare un po 'di confusione, ma dato che ho già scritto abbastanza, non posso permettermi di spiegare tutto, quindi scusa se vedi che sto andando troppo veloce 🙂
Disinserimento del codice
Cominciamo guardando il nostro programma in linguaggio macchina compilato.

Proprio. Christopher Diaz Riveros
Questo è il codice della nostra funzione principale in montaggio, questo è ciò che capisce il nostro processore, la riga a sinistra è l'indirizzo fisico in memoria, il <+ n> è conosciuto come offset, fondamentalmente la distanza dall'inizio della funzione (main) a quell'istruzione (nota come codice operativo). Quindi vediamo il tipo di istruzione (push / mov / callq…) e uno o più registri. Riassumendo possiamo dire che è l'indicazione seguita dalla fonte / origine e dalla destinazione. <return_input> si riferisce alla nostra seconda funzione, diamo un'occhiata.
input_ritorno
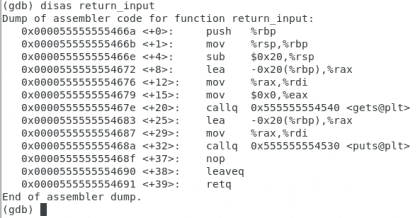
Proprio. Christopher Diaz Riveros
Questo è un po 'più complesso, ma voglio solo che controlli un paio di cose, c'è un tag chiamato <gets@plt> e un ultimo codice operativo chiamato retq indicando la fine della funzione. Metteremo un paio di punti di interruzione, uno nella funzione gets e un altro in retq.

Proprio. Christopher Diaz Riveros
Correre
Ora eseguiremo il programma per vedere come inizia l'azione.
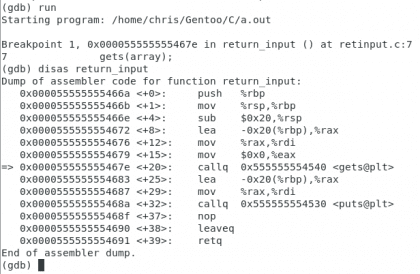
Proprio. Christopher Diaz Riveros
Possiamo vedere che appare una piccola freccia che indica il codice operativo in cui ci troviamo, voglio che tengano conto della direzione 0x000055555555469b, questo è l'indirizzo dopo la chiamata a return_input in funzione main , questo è importante poiché è qui che il programma dovrebbe tornare quando finisci di ricevere il ingresso, entriamo nella funzione. Adesso controlliamo la memoria prima di entrare nella funzione gets.

Proprio. Christopher Diaz Riveros
Ho ripristinato la funzione principale per te e ho evidenziato il codice a cui mi riferivo, come puoi vedere, a causa del endianità è stato separato in due segmenti, voglio che tengano conto della direzione 0x7fffffffdbf0 (il primo da sinistra dopo il commando x/20x $rsp) poiché questa è la posizione che dobbiamo utilizzare per controllare i risultati di gets, continuiamo:
Rompere il programma
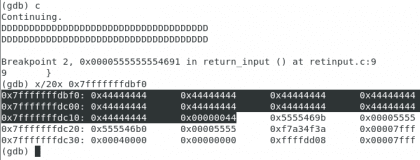
Proprio. Christopher Diaz Riveros
Li ho evidenziati 0x44444444perché sono la rappresentazione delle nostre D 🙂 ora abbiamo iniziato ad aggiungere ingresso al programma e, come puoi vedere, siamo solo a due righe dal nostro indirizzo desiderato, lo riempiremo fino a quando non saremo appena prima degli indirizzi che abbiamo evidenziato nel passaggio precedente.
Modifica del percorso di ritorno
Ora che siamo riusciti ad entrare in questa sezione del codice dove indica il ritorno della funzione, vediamo cosa succede se cambiamo l'indirizzo 🙂 invece di andare nella posizione dell'opcode che segue quello che avevamo un attimo fa, cosa ne pensi se torniamo a return_input? Ma per questo, è necessario scrivere l'indirizzo che vogliamo in binario, lo faremo con la funzione printf da bash 🙂
Proprio. Christopher Diaz Riveros
Ora abbiamo ricevuto le informazioni due volte 😀 sicuramente il programma non è stato fatto per questo, ma siamo riusciti a rompere il codice e fargli ripetere qualcosa che non avrebbe dovuto fare.
riflessioni
Questa semplice modifica può essere considerata a sfruttare molto semplice 🙂 è riuscito a rompere il programma e fare qualcosa che vogliamo che faccia.
Questo è solo il primo passo in un elenco quasi infinito di cose da vedere e aggiungere, ci sono modi per aggiungere più cose che semplicemente ripetere un ordine, ma questa volta ho scritto molto e tutto ciò che riguarda codifica della shell è un argomento da scrivere più che articoli, libri completi direi. Scusa se non sono stato in grado di approfondire un po 'di più gli argomenti che mi sarebbero piaciuti, ma sicuramente ci sarà una possibilità 🙂 Saluti e grazie per essere arrivato qui
Sii più diretto. Scrivi meno e concentrati su ciò che conta
Ciao, grazie per il commento.
A dire il vero ho tagliato una buona parte delle idee, ma anche così mi è sembrato che fosse lasciato il minimo affinché qualcuno che non ha conoscenze di programmazione possa farsi un'idea.
saluti
Il problema è che chi non ha conoscenze di programmazione non scoprirà nulla perché all'inizio è troppo complesso, ma chi sa programmare apprezza di essere più diretto.
Suppongo che non puoi raggiungere tutti, devi scegliere, e in questo caso hai peccato di voler coprire tanto.
A proposito, ti dico come critica costruttiva, adoro questi argomenti e vorrei che continuassi a scrivere articoli, complimenti!
Penso che sia la stessa cosa.
Grazie mille ad entrambi !! È certamente difficile capire come raggiungere il pubblico di destinazione quando la verità è che il numero di persone con un livello avanzato di programmazione che leggono questi articoli è basso (almeno questo può essere dedotto in base ai commenti)
Ho certamente peccato di voler semplificare qualcosa che richiede un'ampia base di conoscenza per essere compreso. Spero che tu capisca che dal momento che ho appena iniziato a bloggare, non ho ancora scoperto il punto esatto in cui i miei lettori sanno e capiscono quello che sto dicendo. Ciò renderebbe molto più facile dire la verità 🙂
Cercherò di essere più corto quando merita senza spersonalizzare il formato, poiché separare il modo di scrivere dal contenuto è un po 'più complicato di quanto si possa immaginare, almeno li ho abbastanza collegati, ma suppongo che alla fine sarò in grado per aggiungere righe invece di tagliare il contenuto.
saluti
Dove potresti saperne di più sull'argomento? Qualche libro consigliato?
L'esempio che ho ottenuto da The Shellcoder's Handbook di Chris Anley, John Heasman, Felix Linder e Gerardo Richarte, ma per fare la traduzione a 64 bit ho dovuto conoscere la mia architettura, il manuale per sviluppatori Intel, i volumi 2 e 3 sono un fonte abbastanza affidabile per questo. È anche utile leggere la documentazione GDB, che viene fornita con il comando 'info gdb', Per imparare Assembly e C ci sono molti libri molto buoni, tranne che i libri di Assembly sono un po 'vecchi quindi c'è un vuoto da riempire con un altro tipo di documentazione.
Lo stesso shellcode non è più così efficace in questi giorni per vari motivi, ma è comunque interessante apprendere nuove tecniche.
Spero che aiuti un po '🙂 Saluti
Buon articolo, vecchio blog desdelinux è rinato di nuovo =)
Quando dici che la shell remota non è così efficace, intendi contromisure progettate per mitigare gli attacchi, la chiamano sicurezza offensiva.
Saluti e continuate così
Grazie mille Franz 🙂 parole molto gentili, in realtà volevo dire che lo Shellcoding oggi è molto più complesso di quello che vediamo qui. Abbiamo l'ASLR (generatore di posizione della memoria casuale), il protettore dello stack, le varie misure e contromisure che limitano il numero di codici operativi che possono essere iniettati in un programma, ed è solo l'inizio.
Saluti,
Ciao, farai un'altra parte espandendo l'argomento? È interessante
Ciao, l'argomento è sicuramente abbastanza interessante, ma il livello di complessità che vorremmo prendere diventerebbe molto alto, coinvolgendo probabilmente un gran numero di post per spiegare i vari prerequisiti per capire l'altro. Probabilmente ne scriverò, ma non saranno i seguenti post, voglio scrivere alcuni argomenti prima di continuare con questo.
Saluti e grazie per la condivisione
Bravissimo che! Stai contribuendo con ottimi post! Una domanda, sto iniziando questa cosa sulla sicurezza IT leggendo un libro intitolato "Assuring security by pen test". Questo libro è consigliato? Come mi suggerisci di iniziare a informarmi su questi problemi?
Ciao cactus, è un intero universo di vulnerabilità e altro, a dire il vero dipende molto da ciò che attira la tua attenzione e dalle esigenze che hai, un manager IT non ha bisogno di sapere come un tester di penna, O un ricercatore di vulnerabilità o un analista forense, un team di ripristino di emergenza ha un insieme di competenze molto diverso. Ovviamente ognuno di loro richiede un diverso livello di conoscenza tecnica, ti consiglio di iniziare a scoprire esattamente quello che ti piace, e iniziare a divorare libri, articoli e altri e, soprattutto, praticare tutto ciò che leggi, anche se non è aggiornato, alla fine farà la differenza.
Saluti,
Hey.
Grazie mille per aver spiegato questo argomento, oltre a commentare che per ulteriori informazioni abbiamo "Manuale di Shellcoder". Ho già una lettura in sospeso 😉