¡Hola Amigos!. Siempre me ha gustado “navegar” por el repositorio. Y hace algún tiempo ya, encontré un paquete que a muchos les puede ayudar en su diario trabajo. Personalmente me ayuda a encontrar artículos o textos o libros, en mi desordenado /home.
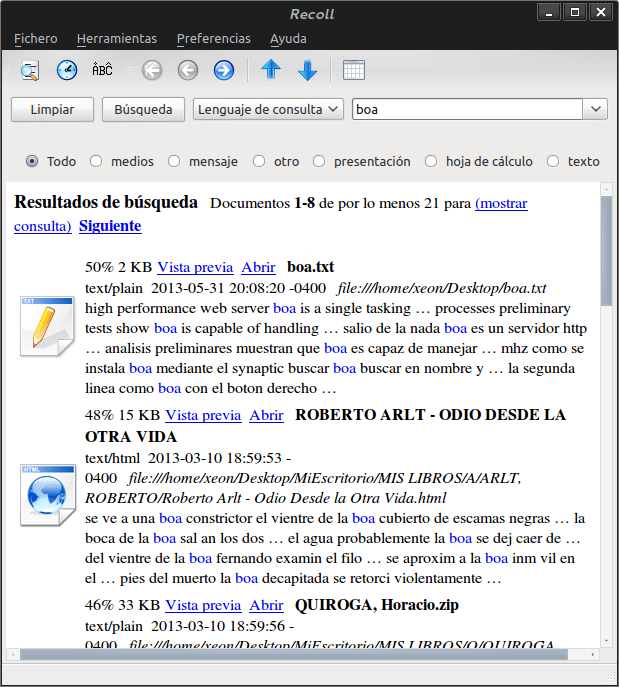
Recoll es una herramienta para la búsqueda de texto completo (desde una palabra hasta expresiones booleanas complejas) mediante una interfaz gráfica amistosa, con un mínimo de técnica sofisticada y algunas obligatorias dependencias externas. Se puede ejecutar en muchos sistemas operativos tipo UNIX, y es bastante independiente del ambiente de escritorio utilizado. No requiere de un demonio como backend para la búsqueda e indexado. Como motor de búsqueda usa Xapian.
Para instalar Recoll, ejecutamos el Synaptic, y en el cuadro de texto “Filtro rápido” tecleamos recoll y enseguida se nos mostrará. Para un uso normal en Debian solo es necesario instalar ese paquete.
Los que prefieren a Ubuntu, pueden instalar además el paquete python-recoll, el cual provee un módulo para extender las funcionalidades de Recoll y emplearlo como un Lens de Ubuntu Unity.
No obstante, recomendamos encarecidamente a los partidarios de Ubuntu lean el artículo Buscando casi todo tipo de archivos en Ubuntu con Recoll, el cual me lo hizo llegar mi amigo Yoandy Pérez Cáceres (Kceres de humanOS). Ese artículo está mucho más amigable que éste.
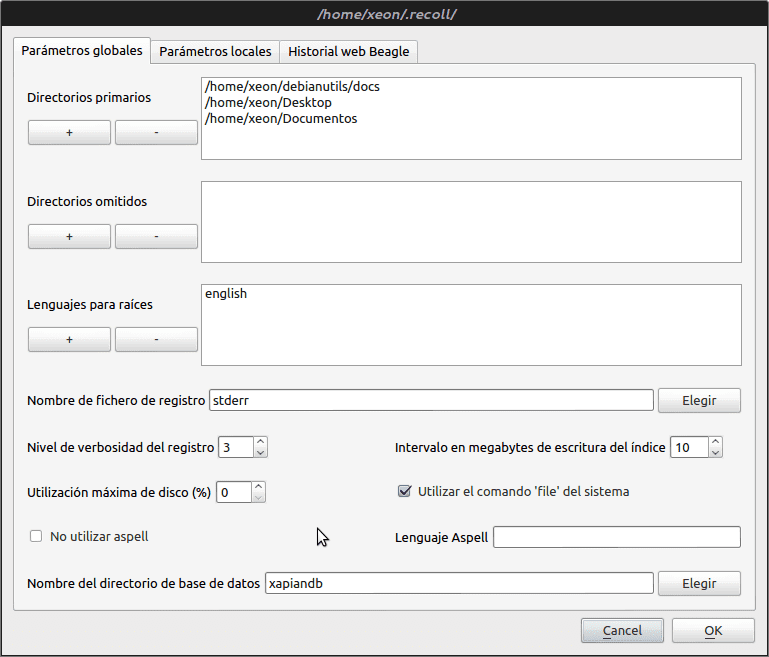
Una vez instalado lo encontraremos en el grupo “Accesorios”. Lo ejecutamos y lo primero que debemos hacer es Configurar la Indexación mediante la opción del menú Preferencias –> Configuración de indexación.
Para que la búsqueda no demore tanto y responda a nuestros intereses, quitamos la virgulilla ~ (significa todo nuestro /home) de los Directorios primarios y añadimos los que consideremos necesarios.
La interfaz gráfica es muy intuitiva, e invitamos a todos a explorar las bondades de este paquete. Comprueben por ustedes mismos el consumo de recursos comprado con los motores de búsqueda que se instalan por defecto con el KDE4, o con el GNOME-Shell.
Además, la sencillez de su instalación y uso, así como la muy corta cantidad de dependencias, lo hace ideal para su trabajo específico en máquinas de poca potencia.
Y hasta la próxima aventura, Amigos!!!.
Entonces esto es algo como lo que hace el Nepomuk? suena bien para usarlo con mi openbox.
¡Gracias por comentar!. Y si, es un buscador de escritorio, pero con mucho menor consumo de recursos
En realidad no creo que llegue a la altura de Nepomuk. Veo que tiene bastantes opciones, pero hay que ver si es capaz de indexar cada elementos por lo que es. Nepomuk es un proyecto enorme, y no creo que Recoll llegue a su nivel, por lo menos no por ahora.
nepomuk es más lento y buggy que el indexador de windows, y eso ya es decir XD
Nepomuk no tiene nada que ver con el indexador de Windows, o al menos así era hasta donde me quedé en Windows.
Nepomuk mejoró muchísimo en KDE 4.10 y será mucho más rápido en KDE 4.11 😀
llevan diciendome lo mismo desde la 4.6…, será mejor y bla bla bla, y no veas las veces que se me ha colgado leyendo mi biblioteca de música japonesa XD
Si, por lo que tengo entendido lo cambiaron totalmente y lo reescribieron, ya no usa strigi
Nepomuk no muestra la parte del texto, y menos la resalta, cuando buscas algo. Esto es superior!!!
Me maté buscando algo así!!!!!
No sabes lo feliz que me has hecho!!!!!!!!
Llegué a intentar instalar un tal Goonepuk (o algo así) que usaba a Nepomuk para buscar texto al estilo Google pero no funco.
Pero esto es ideal (de la emoción todabia no lo instalo 🙂 )
Creí que jamás encontraria algo así, y ensima parece liviano, ideal para mi XFCE (lástima que tiene depen. qt, pero todo no se puede en la vida, ja).
No se cómo agradecertelo, de diste de nuevo sentido a mi vida (bueno, exagero un poco)
¡¡MUCHAS GRACIAS!!!!!!!!!!
Gracias a usted por su comentario. Feliz estoy de que le haya servido. Recuerdo por los años 90 los programas que usaban para las búsquedas. Tremendos!!!. Ahora, con un sencillo programa, se resuelve.
Felicidades!!!.
Si es de de los 90’s, entonces es garantía de que será genial y por lo tanto, mucho mejor (que yo sepa, la mayor parte del software libre hecho en los 90’s eran geniales).
Gracias a todos por comentar!!!. Recoll indexa de forma nativa texto plano, html, maildir, mailbox ( Mozilla, Thunderbird y Evolution mail), gaim, Scribus, páginas Man y diagramas Dia. Con la ayuda de Plugins tales como iconv, xslproc, unzip, pdftotext, antiword, y otros, puede indexar además Abiword, Fb2, Kword, Microsoft Office Open XML, archivos con extensión SVG, Gnumeric, Okular, pdf, MS Word, Wordperfect, Lyx, Powerpoint, Excel, archivos en formato CHM. También puede servir de complemento del Firefox para indexar el histórico de páginas web, o el procesamiento de los archivos adjuntos de los correos electrónicos.
No se el alcance de otros buscadores, pero para mis necesidades, sobran las prestaciones. 🙂
Bueno, en Windows 7 se puede encontrar en archivos docx si no me confundo. Pero seguro que me confundo. Pero si soporta a odt habria que probarlo.
Bien, pero los resultados son diferentes.
Yo no me canso de hablar bien de este programa. Uso un entorno gtk y por lo mismo podría buscar una solución que use librerías de esta familia, pero la alternativa gtk supuestamente potente, tracker, es pésima. Con respecto a Nepomuk, es una locura instalarlo si no usas KDE (de hehco, no sési tenga sentido hacerlo), pues su instalación acarrea casi todo KDE. Además, lo he probado de manera nativa en entorno KDE y la verdad es que no me convence, ni por rendimiento ni por resultados. Recoll ocupa pocos recursos, indexa a a perfección y muestra de manera muy útil los resultados. Por ahora, no cambio por nada esta herramienta.
Saludos.
Gracias por comentar!!!. Recoll se ajusta, y por mucho, a mis necesidades. El motor Xapian -o sus librerías- se utiliza en otras aplicaciones como el Synaptic y uno ni se entera cuando está indexando.
Una consulta: ¿Qué entorno de escritorio usas y qué tema estás usando? Porque el tema que habías usado en GNOME 3 en el tutorial del QEMU-KVM estuvo realmente genial.
si no me equivoco, sospecho que es XFCE con el tema Albatross (el mejor de todos)
@eliotime3000, @gato: Saludos ante todo. Después de usar Cinnamon por un par de semanas, regresé al GNOME-Shell. Si al criticado Shell. Y parecerá raro, pero como dije en la 1era parte del QEMU-KVM, para mi es una bala. Saben que?. Me he adaptado de lo mejor, y eso que para nada soy joven. 🙂 Conseguí las extensiones gnome-shell-classic-systray_0.1-0+20120306~webupd8~precise1_all.deb y la gnome-shell-frippery-0.4.1.tar.gz y la verdad que no extraño en CASI nada al GNOME 2. El fichero tar,gz, contiene 6 extensiones que deben copiar a ~/.local/share/gnome-shell/extensions/, reiniciar el GDM3, y luego con el gnome-tweak-tool configurar el ambiente. Y @gato, si uso el Albatros, que se instala con el paquete shiki-human-theme y sus dependencias.
En fin, me he acostumbrado al GNOME-Shell y se lo recomiendo a todos. Puede que me embulle y haga un post, sobre todo para los recién llegados, de como hacernos un Debian Desktop personalizado.
Excelente herramienta!
Es muy buena. Tarda un poco en crear la base de datos, pero para buscar es muy rápido.
Incluso busca parabras dentro de archivos de LibreOffice e Inkscape (.svg). Es muy útil cuando no sabemos elnombre de un archivo pero sí parte del contenido. Gracias!
Gracias por comentar, Joaquín!!!. El tiempo consumido en la creación de la base de datos, depende de la cantidad de carpetas que le hayas declarado en la configuración. No obstante, no se si comprobaste que, mientras indexa y crea la base, puedes trabajar normalmente.
man grep
Y si usas ubuntu hay una lente que hace que manejarlo sea lo más sencillo del mundo.
Por cierto para instalarlo en ubuntu lo que hay que hacer es instalar los paquetes recoll (para el programa) y recoll-lens (para la lente).
En el artículo al cual hago referencia arriba, «Buscando casi todo tipo de archivos en Ubuntu con Recoll», se da una detallada explicación de como instalar el Recoll en Ubuntu. Gracias por comentar!!!.
Hola fico.
Soy informático y trabajo en el Ayuntamiento de Coria (Cáceres). Estamos implantando Ubuntu y, entre otra utilidades, estamos usando Recoll.
Lo que quiero saber es cómo has conseguido la versión en castellano.
Saludos y gracias.
Creo que yo mismo me contesto.
En los repositorios de Ubuntu está la versión 1.17.3 y la traducción al castellano fue introducida en la versión 1.19.3
Saludos.
Saludos Angel !!!. Pues en Debian 7 «Wheezy», la versión es la 1.17-3.2, y viene traducida. Al parecer los debianeros la empaquetaron a partir de uma versión traducida al español para que pudiera usarse en caso necesario. Creo que puedes descargar una desde el sitio web de Debian.
Acabo de descubrir una opción espectacular. Se puede hacer que recoll indexe archivos sin necesidad ni de iniciar sesión ni de tener interfaz gráfica activa.
Se puede ejecutar automáticamente con el comando recollindex -x -m. El -x es para que funcione sin interfaz gráfica activa (sin las X) y el -m es para que monitorice los archivos en tiempo real (cuando se cree o modifique alguno). Además se puede modificar el archivo de configuración recoll.conf, que suele estar dentro de la carpeta .recoll del home para indicarle que carpetas monitorizar, etc.
Todo esto viene genial para indexar archivos en un servidor por ejemplo.
Luego dentro del gui puedes hacer que a la hora de buscar use índices externos (en preferencias -> configuración de índices externos).
Además me he creado un pequeño script para init.d para hacer que el indexador arranca automáticamente con el inicio del servidor.
Y así desde los equipos de escritorio puedo hacer busquedas de los archivos indexados en el servidor.
Una pasada
Tremendo aporte, amigo Andrés Sánchez !!!. Lo tendré en cuenta para aplicarlo en mis servidores de archivos con Samba. Gracias por el detalle de compartir tu descubrimiento.
Saludos de Federico
De nada hombre. De eso trata esto, de compartir nuestros descubrimientos.
Por cierto, échale un vistazo a la ayuda para configurar el archivo recoll.conf. Se puede cambiar las rutas de indexación (por defecto solo lo hace en el home), omitir archivos y carpetas dentro de esas rutas, especificar si seguir enlaces simbólicos, especificar los lenguajes (idiomas) que se usarán para la indexación, la codificación de los archivos, si la indexación es sensible a mayúsculas, la ruta donde se guardará el indice (esto viene genial para luego acceder al índice desde otro equipo, siempre que la ruta de líndice esté en una carpeta compartida) y muchas otras opciones que aún no he probado.
En la ruta /usr/share/recoll/examples (por lo menos en ubuntu) hay archivos de ejemplo de la configuración.
Hola, soy usuario de OpenSuse (hoy la versión 13.1) y como herramienta de indexación utilizo Google Desktop hace años.! (he leído los problemas que tiene y los huecos de seguridad, blablablabla,) pero hasta ahora no había visto ni encontrado algo que esté a su altura con respecto a los resultado.
Recoll lo vengo usando hace menos de 1 mes y de tan completo que es ya no me está resultando. Es complejo para configurarlo, no está pensado para el usuario común y corriente que no entiende mucho de comandos y esas cosas.
Parece muy prometedor pero hasta el momento no me convence del todo.
Si alguien me puede dar una mano con un problemilla (diría Flanders).
Al momento de instalarlo, antes de la primera indexación del home, decidí agregar varios directorios remotos y del sistema (/usr/share, etc, /mnt/directorio de red interta, /mnt/mi disco lacie para backup,)
El problema que encontré es que cuando ingreso un texto para búsqueda simple, me devuelve como resultado, primero los que están en mis directorios externos («/mnt/….») y por último los que están en /home/mi nombre.
Otro problema es que cuando ingreso como busqueda «DNI mi nombre» (sin comillas) no me devuelve ningún resultado si elijo el filtro «nombre de archivo» cuando el archivo justamente se lla «DNI mi nombre.jpg»
Para que aparezca el archivo debo elegir «todos los términos o cualquier término»
Hasta ahora por cuestiones prácticas, rapidez y sencillez, el google desktop sigue siendo el mejor, al menos que encuentre como configurar el Recoll y como hacer para que priorice los archivos en mi home al momento de devolver los resultados.
Si alguien puede ayudarme o decirme donde puedo encontrar alguna guia sencilla (NO EL MANUAL DE 50MIL páginas y que está en ingles)
Muchas gracias por el post. MUY BUENO.
PD: Nepomuk nunca me sirvió para nada!! nunca vi como sacarle el jugo y como funciona. hablan por todos lados de lo bueno que es pero nunca vi a nadie como sacarle el jugo y como ponerlo en práctica.